

PageRank can be thought of as a model of user behavior. We assume there is a "random surfer" who is given a web page at random and keeps clicking on links, never hitting "back" but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank.
Put another way, the more links to a page, the more ‘votes’ it gets and the higher its PageRank. Adding more complexity to that idea, the votes are weighted by the PageRank of each linking page and tempered by the amount of links that referring page has.
As Si Fiskin expertly points out, there were some critical limitations to this early PageRank model. The final equation documented in the research paper includes adjustments to correct the limitations, as you will understand by reading this post. Let me warn you that this post gets quite mathematical. Brace yourself!
Limitations of the early PageRank
The limitations of the basic model are well documented:
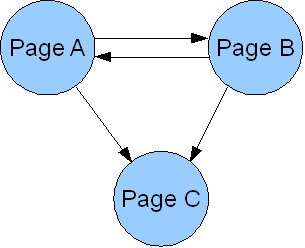
- Rank Sinks. A rank sink occurs when a page does not link out. The PageRank values are calculated by running multiple iterations until the scores stabilize. Rank sinks monopolize scores by refusing to share. In the diagram below, Page C is a rank sink.
- Hoarding. Extending the concept of rank sinks, a group of pages that only link between each other will also monopolize PageRank. Wikipedia is a good example of this, as they use no-follow with all links to external sites. Pages D, E, and F are conspiring to hoard PageRank.
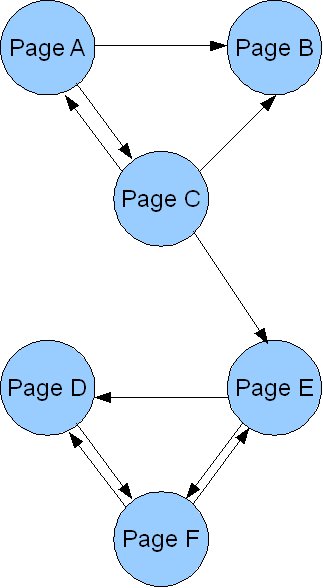
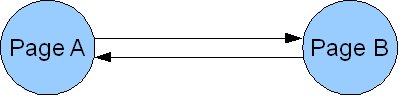
- Circular references. A couple of pages that only link between themselves and do not link to any other page. The iterative process will never converge, as the algorithm is trapped in a never-ending loop.
First adjustment: Stochasticity Adjustment
The PageRank equation involves the use of summations, which is a very tedious process. The hyperlink structure of the Web can alternatively be modeled as a matrix (similar to an Excel spreadsheet). Let's call this matrix H.
Matrices allow those summations to be converted into simpler vector-matrix multiplication, which doesn't require as much computation time. Matrices also take advantage of matrix algebra and Markov Chains theory. In matrix H, the rows and columns are pages and the value (0 or 1) at the intersections indicates whether or not there is a link between the pages. Instead of using 1 to indicate a link, we use 1/x, where x is the number of non-zero elements in each row. This strategy turns the non-zero values into probabilities, and creates a row substochastic matrix. Basically, this means that when you add the values of each row, some of the totals will equal 1 and the rest will equal zero. The zero totals happen because of the dangling nodes or rank sinks. For a row stochastic matrix all the rows must add up to 1.
In addition to the problems mentioned above, leaving the matrix unmodified does not guarantee that the values will ever converge, no matter how many iterations are performed. In order to fix these problems, the first adjustment was introduced. It replaces all zero rows (dangling nodes/rank sinks) with 1/n eT (eT is a row vector of all 1s), making the matrix stochastic. Let's call this modified matrix S. This matrix is the transition probability matrix for a Markov chain.
Intuitively, this adjustment means that for pages that don't want to link out, the modified model automatically creates invisible links so that the algorithm never gets stuck; when the ‘random surfer’ enters a dangling node, he can hyperlink to any page at random.
Second adjustment: Primitivity Adjustment
In addition to solving the problems caused by rank sinks, it is desirable that the PageRank value of all pages is found quickly (in as few iterations as possible). Fortunately, applying the Power Method to a Markov matrix converges to a unique and positive vector called the stationary vector—in our case, the PageRank vector—as long as the matrix is stochastic, irreducible, and aperiodic. (Aperiodicity and irreducibility imply primitivity.)
Intuitively, the primitive adjustment can be thought of as a random surfer that gets bored sometimes while following the hyperlink structure of the Web, and, instead of following links at random, enters a new URL in the browser navigation bar and continues from there. A proportion of the time he will be following links at random and a proportion of the time he will be 'teleporting' to a new URL.
In order to model this mathematically, a new factor is introduced: α, a scalar between 0 and 1. Page and Brin originally defined α as 0.85. For this suggested α, it means that 85% of the time the surfer is following links at random, and 15% of the time he is entering new URLs in the browser bar.
A new matrix is born from this adjustment. Let's call it G, the Google matrix.
G = α S + (1 - α) 1/n eeT or G = α S + (1 - α) E, where E is the teleportation matrix. E = 1/n eeT (remember that eT is a row vector of all 1s)
The teleporting is random because the teleportation matrix E = 1/n eeT is uniform, which means that the random surfer is equally likely to jump to any page when he teleports.
Conclusion
Thanks to the this teleportation behavior of the random surfer and the invisible links that are introduced to compensate for rank sinks, I wouldn't worry much about sites not linking out or the effectiveness of PageRank-hoarding techniques. All these was observed and addressed back in 1998, and I am sure they are using far superior improvements to the PageRank algorithm today. For example, we remember that the Google index updates happened once per month (in part because of the time it took to compute the PageRank of all pages on the Web). Now we know that updates are incremental; most likely, Google has figured out a way to compute Page Rank partially or incrementally.
If you managed to read and absorb all this, I am sure your head hurts as much as mine did writing and researching it. :-) I’ve tried hard to explain this in simpler terms, but unfortunately the math needs to be discussed to fully appreciate the details.
Further reading
Hamlet - I love this post, and I think it's great to have such detailed material out in public like this. My one questions would be - after researching all this, what strategies would you recommend for and against that SEOs might try to use to control the flow of PageRank. The math and theory is obviously fascinating and worthwhile, but the practical application might be of even greater value to the audience here.
Rand - you read my mind!
I second Rand. Or am I third.
Rand - Thanks again for giving me the opportunity to share my insights with you huge audience! what strategies would you recommend for and against that SEOs might try to use to control the flow of PageRank. The math and theory is obviously fascinating and worthwhile, but the practical application might be of even greater value to the audience here.
Sorry, I got so absorbed with the geeky stuff that forgot to include some practical tips.
Here are some of my takeaways:
First, the question: Why do we want to control the flow of PageRank? I believe is to give more PageRank to our important pages and less PageRank to our less important ones. Right?
There are two ways we can give more PageRank to any page:
I need to do some simulations to confirm this, but I think both approaches achieve the same end result. I personally prefer to get more links to the most important pages (this is not always possible or visually appealing). The pages getting the most links will naturally have higher PageRank.
Intuitively, imagine the random surfer is following links on your site. The surfer will end up spending more time on the pages that have more incoming links; so they will end up with higher PageRank. Alternatively, the same happens if we remove links from the less important pages by no-following them. The random surfer will spend less time on the less important pages and more time on the more important ones. Same end result.
It is important to understand that when you no-follow internal pages, you leave an easily detectable footprint that search engineers can use if they want to demote SEO'd sites. I am not saying they are doing it, but I wouldn't be surprised if they did.
The tactic of giving more PageRank to the most important pages (or taking away from the less important ones) makes sense for sites that have pages with reasonably high PageRank. There has to be enough PageRank flowing through the site to make it worthwhile.
Another important tip is that it is a good idea to avoid rank sinks. Why? The link juice will be given to another page on the web at random. It is better approach to link back to some of the pages of the site and keep the juice in the house!
Sorry, I am not sure that quite understand this part:
"Alternatively, the same happens if we remove links from the less important pages by no-following them. The random surfer will spend less time on the less important pages and more time on the more important ones. Same end result"
Is it removing links at all or adding nofollow attribute?
Also you mentiomed 'quality signals' Google is speculated to be using for measuring website value. This part is really interesting. There is no confimed data on this and all we can do is to rely on our observations. Maybe someone here cares to share?
You don't physically remove them, but from the perspective of the random surfer when you no-follow a link, the random surfer won't follow it; so it is like you removed it.
Yes, I agree it is really interesting. I blogged about it a while ago.
OK, I see, thanks a lot, Hamlet
Hey Hamlet,
Thanks for spending the time to think through this stuff. Between you and Andy Beard I think there's enough material for a SEO Master Class.
Andrew
Andrew - Yes. I think I should team up with Andy on that ;-) Great blogger that Andy Beard!
"...I wouldn't worry much about sites not linking out or the effectiveness of PageRank-hoarding techniques. All this was observed and addressed back in 1998, and I am sure they are using far superior improvements to the PageRank algorithm today."
Hamlet,
You mean to tell me that for the last nine years I've been losing sleep over substochastic matrices - not to mention the possiblity of the potential of sufficient conditions for existence of an infinite doubly substochastic matrix - when you've had the answer all along?!!!
Jeez Louise. Next time don't wait so long to share your insight! :)
Excellent post.
LOL. Thanks, seanmag. I promise to share sooner ;-)
Yay. Maths on the 'moz. Nice post Hamlet - I think you've explained it very well. I have a post I half-wrote on the train last night explaining stochastic convergence in simple terms. I'll try to finish it and get it up today if I can.
For the most part, I think all this stuff is good to know (and avoiding 'sinks' is the biggest take-away in practical terms that people might not have known in my opinion) but not *that* useful to day to day SEO. Having said that, like you said, any edge is an edge and we certainly pull some maths from time to time :)
Great! I look forward to that post.
I think that a clearer understanding of the search engines's underpinnings also helps dispel some uncessesary fears.
A couple months ago this would have just flown over my head - and although I'll agree with MrThePlague, my head does hurt.
Excellent piece and it certianly makes a collection of random bits about PR I have read over the past few weeks make much more sense.
Thanks, Chris. I am glad you found it useful.
Good post :)
Hamlet,
The fact that I some how missed this one and am just catching it...wow, over a half-year already is embarassing. What's scary is that the amount of behindness and need for catching up I feel now is no where near what I was feeling when you posted this.
This was a mind-full post...and I think my mind exploded before the end of the H1.
But as always, thanks for such insightful posts...and damn you for posting such posts that I can't even dream of posting. ;)
cheers mate
Hi Brian,
Don't worry I haven't been blogging for a couple of months. I am sure you are really busy at your new job :-)
LOL. Imagine how hard it was for me to read the research material and trying to extract the SEO value. I'm glad you enjoyed it.
I might be a nose ahead on tech side but you are many steps ahead on your compelling writing. All your comments are like high quality blog posts!
I am really looking forward to meeting you at SMX Advanced.
See you soon!
I first learned about Markov Chain in 1965 fom a book by R A Howard of MIT.
It was called Dynamic Programming and Markov Chains.
It was a brilliant explanation wih superb examples
I can't find a copy in any library in either the UK or the USA.
Does anybody have a copy?
Tony Greenfield [email protected]
I did a search and did not find any references to that book. Glad to see math experts commenting, Tony.
I hope you stick around and help us on our quest to learn more. :)
This is very advanced - and I loved it. Thanks for the insight...
What is your opinion on the effect Social Media has had on the random surfer? Do you think the Primitivity Adjustment is unique with every Google update?
Thanks, jameszol.
Any answer I give you will be pure speculation, so I to be honest I have not idea. I believe Google uses a lot more 'quality signals' than just the links to measure the importance of a page or website; but I have not found any research material that validates this. Maybe Bill Slawsky has dugg something out.
Both adjustments are part of the equation and are taken in account every time the PageRank is calculated for every page. They are not a separate step or process.
My brain does hurt ... but wow what a great post! Very informative and bookmarking it for later use.
So .. Google Matrix equals the product of a scalar between 0-1 and the Matrix stochastic Plus the product of 1 minus a a scalar between 0-1 and the teleportation matrix
Thanks, imnotadoctor.
That is correct. It is the same scalar. Originally 0.85.
Sweet ... Thanks for the confirmation!
good post but way more info than I need or care to know about. I just like making pages rank well and I do it without the math. The math is impressive though. If I ever need to baffle a client, I'm going to call you into the meeting. ;) The we can watch as his eyes glaze over just before signing the cheque.
LOL. I guess it all depends on how competitive is your battle on the SERPs ;-) If your competitors are too savvy, every piece of information you have that they don't, counts!
very true.
Nice post first of all! Thanks for the detail! More is welcome whenever you have time to share.
I love this level of sophistication whenever I can get it. I implore Rand to create a separate Blog. You have YOUmoz and SEOmoz. Let's see the COMPUTATIONALLY-INTENSEmoz for advanced mozzers.
I will do my best to understand, but when in doubt trust Rand's linking structure and nofollow usage on SEOmoz. ;)
Thanks, slingshotseo. Unfortunately, I think most of our peers don't like to read this type of material. It is sad because you can get a huge amount of ideas and insights from IR books, patents and research papers.
If you really liked this post, you will love this one. It is easier to follow and provides background information for some of concepts discussed here. On that post, I also introduce the idea of an intelligent surfer -- An improvement over the random surfer model.
"Unfortunately, I think most of our peers don't like to read this type of material."
Hamlet,
I won't say I beg to differ here because I understand the point is valid. However, I would say that the content of pieces like this raises the value of the SEOmoz board to a new level. There are some very sophisticated people in this community and while I myself transferred from an Engineering Science major to Business (simply because my marketing & sales person overruled my technology person), I do have an aptitude to assimilate complex concepts.
That said, although my earlier comment was tongue in cheek, this was a heavy piece and I ended up investing two hours on the net last night researching in order to gain a better understanding of the argument you presented. In other words - it was thought provoking.
I agree with the majority of the folks here that taking your article another step - by providing the synthesis of your argument in a summary as close to layman's terms as possible, coupled with any potential personal recommendations and insight (i.e. takeaways), would put the icing on the cake for an astounding piece of research, and in the process serve a much broader percentage of the community.
Bottom line, this is a contribution consistent with your mantra (which IMHO should be the tagline at the top of your blog):
"...knowing and doing what everybody else does is not a competitive advantage."
You're dead on with that one Hamlet. I applaud you for this effort and implore you to keep them coming. Just by reading your blog, if someone were to ask me to describe in one word what I think of Hamlet Batista, I would respond:
"Hamlet is an AUTHORITY on SEO that presents his ideas in an unassuming manner and who challenges people to look outside the box and think". Can you see the word?
On a final note, if there's a MOZblog Hall of Fame (Rand?), this article deserves entry.
seanmag, I feel deeply touched by your words. You left me speechless. Honestly!
It confirms my believe that while building your reputation they way I am doing it, is definitely slower and harder, then end result is definitely worth it. Thanks!
I will do my best to keep sharing my research with the SEO community.
"It confirms my believe that while building your reputation they way I am doing it, is definitely slower and harder, then end result is definitely worth it."
Without question.
To the rest of your response - you're welcome. Judging by the "air time" you received on some of the other posts today, I think it further confirms your approach.
On a separate note, I'm looking forward to seeing RankSense in action.
P.S. It looks like you are using the same blog theme as Chris Pearson. I'm just curious if it is custom, or if the basic theme is out there? I'm debating between using that or Revolution by Brian Gardner. Any thoughts?
Thanks again, Sean.
You should receive your invite this week. Although it is beta software, we want our testers to have a positive experience with the software. We are integrating the user's guide and doing some performance improvements at the moment. Stay tuned, and thanks for the interest.
In reality, I use a custom built theme. I did point the designer to a few blogs for inspiration. Chris was one of those. Nice catch!
Honestly, I wouldn't know which theme I would recommend you use. It is mostly a matter of personal preference. A custom one is better for branding, though.
Looking forward to the beta. I totally understand and would help with any bugs. Have significant experience in that area.
On the theme - I definitely plan on "custom", although I'd like to use a well constructed framework as a base. I appreciate the feedback.
Very informative and interesing post - and yes, my head does hurt! I think I'm going to have to read over this a couple more times to let it all sink in!
Thanks, MrThePlague.
"and yes, my head does hurt!"
The more you read similar stuff the less it hurts :-)
Great Post! But I think if I try to explain this to clients their minds could possibly melt.
But great post!
Thanks, angle45media. You are probably right!