
I am a huge Portland Trail Blazers fan, and in the early 2000s, my favorite player was Rasheed Wallace. He was a lightning-rod of a player, and fans either loved or hated him. He led the league in technical fouls nearly every year he was a Blazer; mostly because he never thought he committed any sort of foul. Many of those said technicals came when the opposing player missed a free-throw attempt and ‘Sheed’ passionately screamed his mantra: “BALL DON’T LIE.”
‘Sheed’ asserts that a basketball has metaphysical powers that acts as a system of checks and balances for the integrity of the game. While this is debatable (ok, probably not true), there is a parallel to technical SEO: marketers and developers often commit SEO fouls when architecting a site or creating content, but implicitly deny that anything is wrong.
As SEOs, we use all sorts of tools to glean insight into technical issues that may be hurting us: web analytics, crawl diagnostics, and Google and Bing Webmaster tools. All of these tools are useful, but there are undoubtedly holes in the data. There is only one true record of how search engines, such as Googlebot, process your website. These are web server logs. As I am sure Rasheed Wallace would agree, logs are a powerful source of oft-underutilized data that helps keep the integrity of your site’s crawl by search engines in check.

A server log is a detailed record of every action performed by a particular server. In the case of a web server, you can get a lot of useful information. In fact, back in the day before free analytics (like Google Analytics) existed, it was common to just parse and review your web logs with software like AWStats.
I initially planned on writing a single post on this subject, but as I got going I realized that there was a lot of ground to cover. Instead, I will break it into 2 parts, each highlighting different problems that can be found in your web server logs:
- This post: how to retrieve and parse a log file, and identifying problems based on your server’s response code (404, 302, 500, etc.).
- The next post: identifying duplicate content, encouraging efficient crawling, reviewing trends, and looking for patterns and a few bonus non-SEO related tips.
Step #1: Fetching a log file
Web server logs come in many different formats, and the retrieval method depends on the type of server your site runs on. Apache and Microsoft IIS are two of the most common. The examples in this post will based on an Apache log file from SEOmoz.
If you work in a company with a Sys Admin, be really nice and ask him/her for a log file with a day’s worth of data and the fields that are listed below. I’d recommend keeping the size of the file below 1 gig as the log file parser you’re using might choke up. If you have to generate the file on your own, the method for doing so depends on how your site is hosted. Some hosting services store them in your home directory in a folder called /logs and will drop a compressed log file in that folder on a daily basis. You’ll want to make sure to it includes the following columns:
- Host: you will use this to filter out internal traffic. In SEOmoz’s case, RogerBot spends a lot of time crawling the site and needed to be removed for our analysis.
- Date: if you are analyzing multiple days this will allow you to analyze search engine crawl rate trends by day.
- Page/File: this will tell you which directory and file is being crawled and can help pinpoint endemic issues in certain sections or with types of content.
- Response code: knowing the response of the server -- the page loaded fine (200), was not found (404), the server was down (503) -- provides invaluable insight into inefficiencies that the crawlers may be running into.
- Referrers: while this isn’t necessarily useful for analyzing search bots, it is very valuable for other traffic analysis.
- User Agent: this field will tell you which search engine made the request and without this field, a crawl analysis cannot be performed.
Apache log files by default are returned without User Agent or Referrer -- this is known as a “common log file.” You will need to request a “combine log file.” Make your Sys Admin’s job a little easier (and maybe even impress) and request the following format:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-agent}i\""
For Apache 1.3 you just need “combined CustomLog log/acces_log combined”
For those who need to manually pull the logs, you will need to create a directive in the httpd.conf file with one of the above. A lot more detail here on this subject.
Step #2: Parsing a log file
You probably now have a compressed log file like ‘mylogfile.gz’ and it’s time to start digging in. There are myriad software products, free and paid, to analyze and/or parse log files. My main criteria for picking one includes: the ability to view the raw data, the ability to filter prior to parsing, and the ability to export to CSV. I landed on Web Log Explorer (https://www.exacttrend.com/WebLogExplorer/) and it has worked for me for several years. I will use it along with Excel for this demonstration. I’ve used AWstats for basic analysis, but found that it does not offer the level of control and flexibility that I need. I’m sure there are several more out there that will get the job done.
The first step is to import your file into your parsing software. Most web log parsers will accept various formats and have a simple wizard to guide you through the import. With the first pass of the analysis, I like to see all the data and do not apply any filters. At this point, you can do one of two things: prep the data in the parse and export for analysis in Excel, or do the majority of the analysis in the parser itself. I like doing the analysis in Excel in order to create a model for trending (I’ll get into this in the follow-up post). If you want to do a quick analysis of your logs, using the parser software is a good option.
Import Wizard: make sure to include the parameters in the URL string. As I will demonstrate in later posts this will help us find problematic crawl paths and potential sources for duplicate content.
You can choose to filter the data using some basic regex before it is parsed. For example, if you only wanted to analyze traffic to a particular section of your site you could do something like:
Once you have your data loaded into the log parser, export all spider requests and include all response codes:
Once you have exported the file to CSV and opened in Excel, here are some steps and examples to get the data ready for pivoting into analysis and action:
1. Page/File: in our analysis we will try to expose directories that could be problematic so we want to isolate the directory from the file. The formula I use to do this in Excel looks something like this.
Formula: <would like to put this is a textbox of some sort>
=IF(ISNUMBER(SEARCH("/",C29,2)),MID(C29,(SEARCH("/",C29)),(SEARCH("/",C29,(SEARCH("/",C29)+1)))-(SEARCH("/",C29))),"no directory")
2. User Agent: in order to limit our analysis to the search engines we care about, we need to search this field for specific bots. In this example, I’m including Googlebot, Googlebot-Images, BingBot, Yahoo, Yandex and Baidu.
Formula (yeah, it’s U-G-L-Y)
=IF(ISNUMBER(SEARCH("googlebot-image",H29)),"GoogleBot-Image", IF(ISNUMBER(SEARCH("googlebot",H29)),"GoogleBot",IF(ISNUMBER(SEARCH("bing",H29)),"BingBot",IF(ISNUMBER(SEARCH("Yahoo",H29)),"Yahoo", IF(ISNUMBER(SEARCH("yandex",H29)),"yandex",IF(ISNUMBER(SEARCH("baidu",H29)),"Baidu", "other"))))))
Your log file is now ready for some analysis and should look something like this:
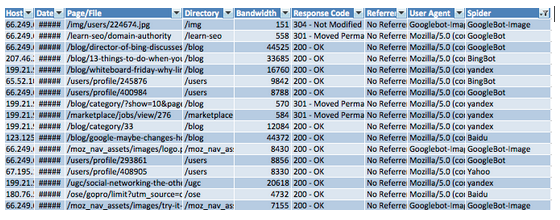
Let’s take a breather, shall we?
Step # 3: Uncover server and response code errors
The quickest way to suss out issues that search engines are having with the crawl of your site is to look at the server response codes that are being served. Too many 404s (page not found) can mean that precious crawl resources are being wasted. Massive 302 redirects can point to link equity dead-ends in your site architecture. While Google Webmaster Tools provides some information on such errors, they do not provide a complete picture: LOGS DON’T LIE.
The first step to the analysis is to generate a pivot table from your log data. Our goal here is to isolate the spiders along with the response codes that are being served. Select all of your data and go to ‘Data>Pivot Table.’
On the most basic level, let’s see who is crawling SEOmoz on this particular day:
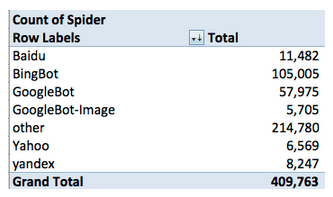
There are no definitive conclusions that we can make from this data, but there are a few things that should be noted for further analysis. First, BingBot is crawling the site at about an 80% more clip. Why? Second, ‘other’ bots account for nearly half of the crawls. Did we miss something in our search of the User Agent field? As for the latter, we can see from a quick glance that most of which is accounting for ‘other’ is RogerBot -- we’ll exclude this.
Next, let’s have a look at server codes for the engines that we care most about.
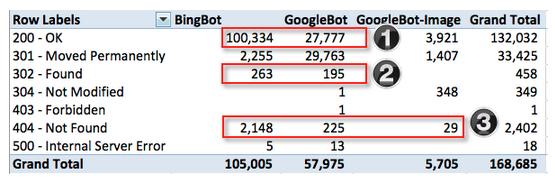
I’ve highlighted the areas that we will want to take a closer look. Overall, the ratio of good to bad looks healthy, but since we live by the mantra that “every little bit helps” let’s try to figure out what’s going on.
1. Why is Bing crawling the site at 2x that of Google? We should investigate to see if Bing is crawling inefficiently and if there is anything we can do to help them along or if Google is not crawling as deep as Bing and if there is anything we can do to encourage a deeper crawl.
By isolating the pages that were successfully served (200s) to BingBot the potential culprit is immediately apparent. Nearly 60,000 of 100,000 pages that BingBot crawled successfully were user login redirects from a comment link.
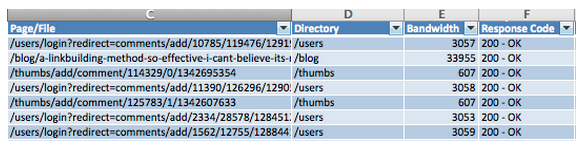
The problem: SEOmoz is architected in such a way that if a comment link is requested and JavaScript is not enabled it will serve a redirect (being served as a 200 by the server) to an error page. With nearly 60% of Bing’s crawl being wasted on such dead-ends, it is important that SEOmoz block the engines from crawling.
The solution: add rel=’nofollow’ to all comment and reply to comment links. Typically, the ideal method for telling and engine not to crawl something is a directive in the robots.txt file. Unfortunately, that won’t work in this scenario because the URL is being served via the JavaScript after the click.
GoogleBot is dealing with the comment links better than Bing and avoiding them altogether. However, Google is crawling a handful of links sucessfully that are login redirects. Take a quick look at the robots.txt and you will see that this directory should probably be blocked.
2. The number of 302s being served to Google and Bing is acceptable, but it doesn’t hurt to review in case there are better ways for dealing with some of edge cases. For the most part SEOmoz is using 302s for defunct blog category architecture that redirects the user to the main blog page. They are also being used for private message pages /message, and a robots.txt directive should exclude these pages from being crawled at all.
3. Some of the most valuable data that you can get from your server logs are links that are being crawled that resolve in a 404. SEOmoz has done a good job managing these errors and does not have an alarming level of 404s. A quick way to identify potential problems is to isolate 404s by directory. This can be done by running a pivot table with “Directory” as your row label and count of “Directory” in your value field. You’ll get something like:
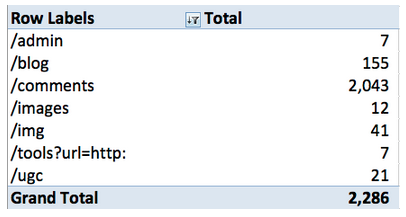
The problem: the main issue that’s popping here is 90% of the 404s are in one directory, /comments. Given the issues with BingBot and the JavaScript driven redirect mentioned above this doesn’t really come as a surprise.
The solution: the good news is that since we are already using rel=’nofollow’ on the comment links these 404s should also be taken care of.
Conclusion
Google and Bing Webmaster tools provide you information on crawl errors, but in many cases they limit the data. As SEOs we should use every source of data that is available and after all, there is only one source of data that you can truly rely on: your own.
LOGS DON’T LIE!
And for your viewing pleasure, here's a bonus clip for reading the whole post.
Nowadays log analysis is essential in every SEO schedule, especially when you have to deal with huge sites.
The mistake, in fact, is in relying only on "classic" Google Analytics metrics, which are not telling us all the truth (especially when the samples are very small percentage of all the visits). And GWT too is not really offering us a deep look in what is going wrong or bad (even if it can guide us in a log analysis focus).
The ideal? Something that could cross the users data (GA) and bots traffic (Logs).
Totally agree, yet there are still SEO's out there that never dive into server logs or even know what they are or how to pull them!
In regards to your ideal, it is somewhat possible with other tracking solutions apart from GA. Analytic trackers like statcounter.com that give you user IP along with data can be matched up to server log data, however not as insightful as GA metrics would allow.
Crossing GA data and log data is something that can easily be done in Excel. Let's say you have two spreadsheets of data: one for GA search traffic by landing pages and the other for log data for the same time period. If you wanted to match up the data you can use the Excel function VLOOKUP to match data by a common key such as landing page. In this case it could be useful to compare crawl rate to actual traffic. I'll get into this a bit in part 2 :)
You can export both log file and Google analytics data to CSV. Then, you can load them into database (Access and MYSQL are the easiest to use) and perform different SQL queries on that data.
Great post!
Even though Google Analytics is easier to use than analyzing server log, you should also do some analysis on logs.
I believe that you can use server logs to get more accurate data about pageviews per visit. The cookies that Google use to determine pageviews per visit lasts only 30 minutes. I often spend more than 30 minutes on one page. When I go to another page, Google will count that as new visit. IP address would be the same on both pagevievs in this case.
Also, Google Analytics needs enabled Javascript in order to work. As not every user have Javascript enabled, you will never get data about these visits. Server log would record these visits.
And finally, thanks for the link to Breather. Some relaxation will certainly help after lengthy analysis ;)
Nice Post I always use logs for SEO... Thanks for nice post
wow..such a great post no one focus on this area these days. Although this is very important side of SEO.
I have some technical SEO to be doing...
This analysis also help users to find out broken,dead-end or unnecessary links. And this is what Google is trying to explain to webmasters. Give up being obsessive about the rank parameters turn your face to your site and users.
Very true but you also have to consider the SEO 'rules' Google has put into place. UK local newspapers just wanted to sell advertisements and Interflora purchased them to advertise for V-day and they all got banned. A normal business transaction for both parties which resulted in Google slapping all of them. So you really have to pay attention to both Google and your users.
+1
Thanks. Very useful tip...
Rip City! :)
Interesting insight and well done to identify Bing as wasting so much time to crawl login pages. I would however like to add a small correction with regards to the following statement - just to avoid a confusion:
"SEOmoz is architected in such a way that if a comment link is requested and JavaScript is not enabled it will serve a redirect (being served as a 200 by the server) to an error page."
1) There is no way for a server to serve redirect with 200 OK. The server either serves redirect (301/302/307) or it serves 200 OK. Serving redirect as 200 OK is not possible.
What actually happens on SEOMoz site is that upon clicking on [+ Add Comment], the URL created by javascript is URL of login page with query string that contains part of the original post URL.
The server, when this login page is requested, responds with 200 OK and shows popup login/register window. Entering login/registration details and clicking on [Login] button then executes POST to the same login URL. On receiving POST and on verifying login details, the server then responds with 302 redirect to the original post page from which the user logged in.
As you can see, the first GET of the login page was served with 200 OK, and then the subseqent POST of the login page that gets requested upon filling in the form responded with 302 redirect to original page from which the [+Add Comment] was clicked on.
The above only happens if the javascript is ENABLED.
2) If javascript is DISABLED, then nothing happens. Click on [+ Add Comment] does not lead anywhere as it is not possible to create the URL since the creation of URL is in external javascript (in fact placed in post_thumb.121011.js )
I guess that the information that Bing gets on these URLs is either via some toolbar or via (IE) browser info. It is not possible to engineer login_register URL without having the access at the same time to both, the post page and the above named javascript. So unless you see Bing requesting javascript immediately after requesting the post page, then it is theoretically possible for Bing to look up for the above javascript within its cached info and use that version to execute javascript and re-create URL - but I am doubtful in that.
In the case of Bing, just in case it caches the javascript, the simpliest solution would be to stop access to the above javascript via robots.txt in which case no URL could be re-created even if bots somehow would want to cache external javascript and execute it, as stopping it via robots.txt would result in boots not being able to look up what is in there.
The alternate of stopping login_register URL via robots would result in many URLs being stopped by robots (each login_register with a different query string of the post page), whereas stopping javascript that creates URL via robots would result only one login_register URL since it would not be possible to create multiples of these as there would be no qs variable created.
Personally I'm using LogFaces, so far I'm more than satisfied: https://www.moonlit-software.com/
I ran across your post today and am dumbfounded. I had no idea how to do any of this. I also never realized how viewing and making sense of my web logs could help my SEO. I am constantly having issues with my Google Ranks. I've been on the first page for a keyword, then a few days later, I'm nowhere to be found. I definitely need to get a handle on what I am doing wrong or what I need to fix. This was a HUGE help. Thanks
I tried to do some log analysis on my own some time ago but after reading your post I must admit I was omitting some important aspects. Thanks for this great guide.
And also thanks for the gem you slipped into your post, the link to calm.com ;)
I always use logs for SEO... Thanks for nice post
Hi Tim Resnik. Your post is good. I got more benefits from your post. I recently used that link of Youtube of Rasheed Wallace about "ball Don't lie". One of my client used to pay hiding many queries and deals he actually gets from the website and he used to provide fake number while paying the incentives. He do not know about the Goal set up in Google analytics about each conversion of client in take form. It is true that "Logs don't lie"
Great post! I've always heard how helpful server logs can be for SEO, but I didn't know exactly how to go about analyzing them.
Now on to Part 2. :-)
Hi Tim,
This article is most useful to me. I do have one question. I use Varnish for the caching of my website. Would I need to get these serverlogs instead of the serverlogs of my hosting to get the right GET requestst Googlebot sends out?
Thanks in advance!
I don't know a ton about Varnish, but found the following about extracting log files from Varnish.
Good article. You used WebLogExplorer to output the raw log data into a nice CSV for Excel. There's also an app I found called Splunk (free version available) that will read the log files and give you a good CSV output. It gave me the file request and directories already separated, so I didn't need to perform that function in Excel.
Thanks for sharing this article. I read it before going on to the new one.
Thanks for walking us through the whole process, Tim! I just stumbled on a quick tip I thought I'd mention since it wasn't immediately obvious to me: save a step (of filtering out internal traffic) by analyzing logs from over the weekend. May not work for everyone, or be appropriate for all applications, but any work saved with these huge log files can be a timesaver.
This is very good information about seo. It's valuable information. Thanks for posting this.
Loved this post Tim. I didn't know you could see this sort of information in your server log. Really interesting. I'm starting to get more into technical SEO, and this was great.
Really nice post. Thanks for sharing. I am looking forward the the next instalment. I will definitely be using this for some of my sites moving forward!
I never did, but i am crazy now to do this on my server log. A very informative & in depth post. :)
Rasheed Wallace - what a crazy dude!
But, let me get this straight, he would get technical fouls simply because he would yell out "Balls don't lie!"?
That doesn't seem fair at all. There have plenty of other players over the years who were just plain dirty, but hardly got regular fouls called on them.
Anyway...
Good post about the server logs. I'll have to dig into this, as it is not something I've got much experience with (mostly rely on Google Analytics). Looking forward to the part 2.
Check out the link to the video at the end of the post. You'll understand why the officials "T" him up. He's quite demonstrative.
Despite the reputation he earned, I always thought of him as a "good" guy. For a big man, he could certainly shoot the 3.
Yeah, I suppose he just had an issue with authority. He was actually loved by teammates and known as a good locker room guy.
I love server log posts. Thanks for sharing Tim!
Are those windows screen shots - painful ;o)
your pal,
Chenzo
Wow, very informative post. I can't wait to dig in and analyze my server logs now. Looks like my week just got a lot busier......
:)
#3 part 3 - a lot of times what I uncover from this is something extra to add to the .htacess file. Finding 404's for admin folders are a clear sign that it should be noindexed, we don't want google crawling pages that weren't meant for users!
Great post! I've been itching to dig into our server logs, and this post is a great first step. Can't wait for part 2.
Hi Tim! You got a very informative post here. I tend to agree with you that as SEOs, we use all kind of tools to gather insight into technical issues that may be hurting us like web analytics, crawl diagnostics, and Google and Bing Webmaster tools. All of these tools are indeed very useful and powerful. I would also recommend that other SEOs must use these tools.
Thanks for sharing Tim. Really enjoyed the deep content, explanation, and screenshots. Very actionable data!
Interesting post and a nice tutorial on pulling this data. Thanks for the post.
A very interesting and informative post. Thanks for that. Look forward to more.
very informative, I have not though of this. Thanks
bing? no offense intended to the author of course, but seriously - why does anyone involved in seo care about bing? it's a joke - and a pretty bad one.
microsoft hasn't a clue, and bing's market share is so pitifully small that it's simply not relevant.
good seo/sem requires a lot of quality effort just to stay on top of things with google - there's way too much work involved to waste any of it on a losing proposition like bing.
sorry, microsoft, but stick to what you do best. you've proven that you don't diversify well - probably your best chance for survival is to pour every ounce of talent and money you have into making office a google-untouchable cloud-based suite.
Very Informative post
Thanks Tim Resnik for sharing this