

Here at Moz we have committed to making Link Explorer as similar to Google as possible, specifically in the way we crawl the web. I have discussed in previous articles some metrics we use to ascertain that performance, but today I wanted to spend a little bit of time talking about the impact of robots.txt and crawling the web.
Most of you are familiar with robots.txt as the method by which webmasters can direct Google and other bots to visit only certain pages on the site. Webmasters can be selective, allowing certain bots to visit some pages while denying other bots access to the same. This presents a problem for companies like Moz, Majestic, and Ahrefs: we try to crawl the web like Google, but certain websites deny access to our bots while allowing that access to Googlebot. So, why exactly does this matter?
Why does it matter?
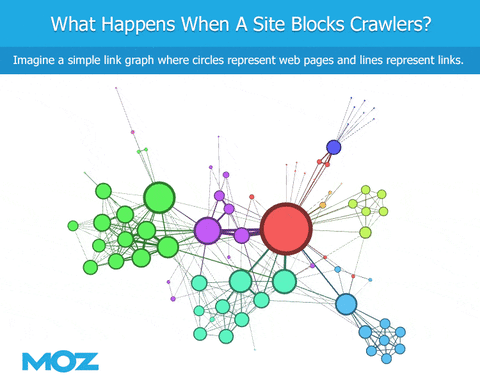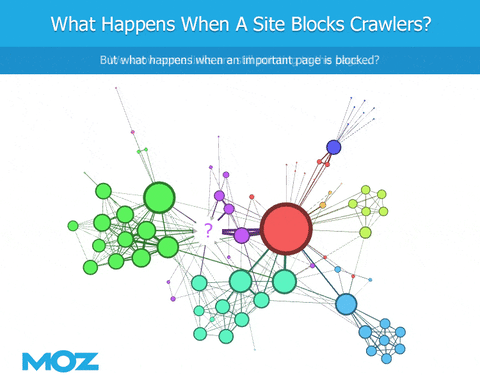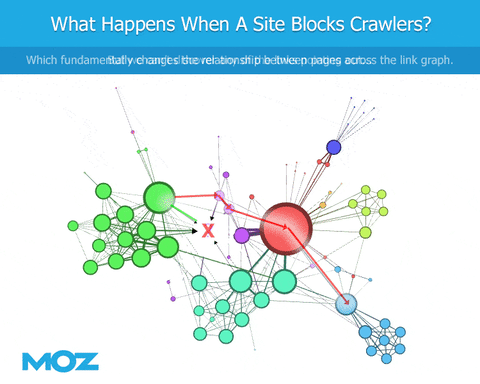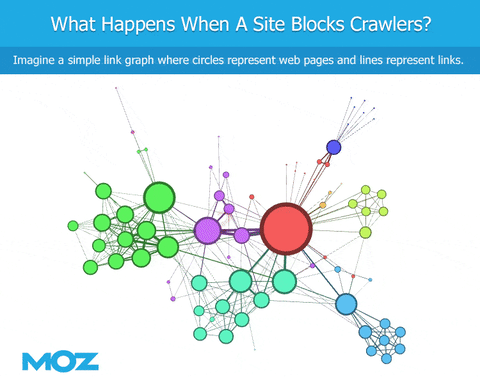
As we crawl the web, if a bot encounters a robots.txt file, they're blocked from crawling specific content. We can see the links that point to the site, but we're blind regarding the content of the site itself. We can't see the outbound links from that site. This leads to an immediate deficiency in the link graph, at least in terms of being similar to Google (if Googlebot is not similarly blocked).
But that isn't the only issue. There is a cascading failure caused by bots being blocked by robots.txt in the form of crawl prioritization. As a bot crawls the web, it discovers links and has to prioritize which links to crawl next. Let's say Google finds 100 links and prioritizes the top 50 to crawl. However, a different bot finds those same 100 links, but is blocked by robots.txt from crawling 10 of the top 50 pages. Instead, they're forced to crawl around those, making them choose a different 50 pages to crawl. This different set of crawled pages will return, of course, a different set of links. In this next round of crawling, Google will not only have a different set they're allowed to crawl, the set itself will differ because they crawled different pages in the first place.
Long story short, much like the proverbial butterfly that flaps its wings eventually leading to a hurricane, small changes in robots.txt which prevent some bots and allow others ultimately leads to very different results compared to what Google actually sees.
So, how are we doing?
You know I wasn't going to leave you hanging. Let's do some research. Let's analyze the top 1,000,000 websites on the Internet according to Quantcast and determine which bots are blocked, how frequently, and what impact that might have.
Methodology
The methodology is fairly straightforward.
- Download the Quantcast Top Million
- Download the robots.txt if available from all top million sites
- Parse the robots.txt to determine whether the home page and other pages are available
- Collect link data related to blocked sites
- Collect total pages on-site related to blocked sites.
- Report the differences among crawlers.
Total sites blocked
The first and easiest metric to report is the number of sites which block individual crawlers (Moz, Majestic, Ahrefs) while allowing Google. Most site that block one of the major SEO crawlers block them all. They simply formulate robots.txt to allow major search engines while blocking other bot traffic. Lower is better.

Of the sites analyzed, 27,123 blocked MJ12Bot (Majestic), 32,982 blocked Ahrefs, and 25,427 blocked Moz. This means that among the major industry crawlers, Moz is the least likely to be turned away from a site that allows Googlebot. But what does this really mean?
Total RLDs blocked
As discussed previously, one big issue with disparate robots.txt entries is that it stops the flow of PageRank. If Google can see a site, they can pass link equity from referring domains through the site's outbound domains on to other sites. If a site is blocked by robots.txt, it's as though the outbound lanes of traffic on all the roads going into the site are blocked. By counting all the inbound lanes of traffic, we can get an idea of the total impact on the link graph. Lower is better.

According to our research, Majestic ran into dead ends on 17,787,118 referring domains, Ahrefs on 20,072,690 and Moz on 16,598,365. Once again, Moz's robots.txt profile was most similar to that of Google's. But referring domains isn't the only issue with which we should be concerned.
Total pages blocked
Most pages on the web only have internal links. Google isn't interested in creating a link graph — they're interested in creating a search engine. Thus, a bot designed to act like Google needs to be just as concerned about pages that only receive internal links as they are those that receive external links. Another metric we can measure is the total number of pages that are blocked by using Google's site: query to estimate the number of pages Google has access to that a different crawler does not. So, how do the competing industry crawlers perform? Lower is better.

Once again, Moz shines on this metric. It's not just that Moz is blocked by fewer sites— Moz is blocked by less important and smaller sites. Majestic misses the opportunity to crawl 675,381,982 pages, Ahrefs misses 732,871,714 and Moz misses 658,015,885. There's almost an 80 million-page difference between Ahrefs and Moz just in the top million sites on the web.
Unique sites blocked
Most of the robots.txt disallows facing Moz, Majestic, and Ahrefs are simply blanket blocks of all bots that don't represent major search engines. However, we can isolate the times when specific bots are named deliberately for exclusion while competitors remain. For example, how many times is Moz blocked while Ahrefs and Majestic are allowed? Which bot is singled out the most? Lower is better.

Ahrefs is singled out by 1201 sites, Majestic by 7152 and Moz by 904. It is understandable that Majestic has been singled out, given that they have been operating a very large link index for many years, a decade or more. It took Moz 10 years to accumulate 904 individual robots.txt blocks, and took Ahrefs 7 years to accumulate 1204. But let me give some examples of why this is important.
If you care about links from name.com, hypermart.net, or eclipse.org, you can't rely solely on Majestic.
If you care about links from popsugar.com, dict.cc, or bookcrossing.com, you can't rely solely on Moz.
If you care about links from dailymail.co.uk, patch.com, or getty.edu, you can't rely solely on Ahrefs.
And regardless of what you do or which provider you use, you can't links from yelp.com, who.int, or findarticles.com.
Conclusions
While Moz's crawler DotBot clearly enjoys the closest robots.txt profile to Google among the three major link indexes, there's still a lot of work to be done. We work very hard on crawler politeness to ensure that we're not a burden to webmasters, which allows us to crawl the web in a manner more like Google. We will continue to work more to improve our performance across the web and bring to you the best backlink index possible.
Thanks to Dejan SEO for the beautiful link graph used in the header image and Mapt for the initial image used in the diagrams.
Fantastic research!
Have to wonder if this is cause and effect. Many webmasters block robots after finding them in their server logs. Since Ahrefs/Majestic previously crawled more sites up until now, it would make sense that they are blocked more often.
If this is the case, it's easy to speculate that Moz may be added to a proportional # of robots.txt moving forward.
Cost of success :) Thoughts?
exactly my thoughts, Cyrus :)
A "cost of success" is one way of putting it, but it is also a "threat of existence". Backlink index crawlers must balance politeness with pervasiveness if they want to continue to offer a valuable product to their customers.
Being blocked is a function of time and speed. Crawlers that have been active for a very long time will likely collect some blocks, even if they are very polite. Crawlers that have been active only a short time but are aggressive will collect blocks very quickly. Majestic has been crawling the longest and probably the 2nd most aggressive of the group compared. Ahrefs has been crawling the shortest but with the most aggressive crawlers. Moz has been crawling the 2nd longest but with very polite crawlers.
We are addressing our crawlers as a part of our beta, but I doubt we will modify our politeness much. We will crawl wider rather than deeper in most cases in order to prevent exactly these kinds of problems.
Since it is highly unlikely that anyone would block all bots from crawling their website, isn't it tmore than likely that crawlers will use multiple user-agents in order to have a realistic profile of backlinks?
Actually, the most common type of robots.txt block we encounter is a blanket dismissal of all bots except major search engines - ie: block all and explicitly allow google, bing, yahoo, baidu, etc.
To my knowledge, Moz, Majestic and Ahrefs all abide by the Robots.txt protocol strictly and do not surf with different UAs just to bypass the rules. This would be highly unethical, IMHO.
Fair points Russ. I suppose it's all speculation as to why.
And certainly not to distract from your main point, which is that according to the data, Moz currently has the most allowed crawler out of the major tool providers.
Great job! Thanks for sharing this with us. It is very important to pay close attention to the robots.txt file, the best way to tell Google where to go and not.
Thank your for the amazing tips!
Great Insight Russ Jones,
People at Moz are working hard and we see the improvement.
Webowners block sites because they might see some logs in their server from bots of these website which are not their target., resulting sites get block from crawling. But I'm sure this not be the case with Moz.
Cheers.
Is Moz stats for DotBot or RogerBot or both?
Very good question - that could make a difference
DotBot.
RogerBot is our site-crawl bot. It is different. You would never see RogerBot in your logs UNLESS you were a MozPro user and used our site crawl tool.
Hi Russ,
This is an interesting one.
Since RogerBot only crawls MozPro user sites, it shouldn't be blocked very often - unless a user really needs to control the RogerBot crawl.
I would love to see the same stats that include DotBot and RogerBot combined - or at least include RogerBot where it has been added as:
User-agent: rogerbot
Disallow: /
If it's added this way, it's likely that the user had the intention of blocking DotBot instead.
If you do a quick Google search for something like "how to hide backlinks from competitors", there is a surprising amount of incorrect information out there that recommends blocking RogerBot with no mention of DotBot.
Something to consider when looking at this data...
Cheers,
David
I did a quick glance for mentions in robots.txt from a sample.
RogerBot: 909
AhrefsBot: 8423
Dotbot: 6213
Majestic: 15740
So even if you assumed every RogerBot block was a mistaken attempt to block Dotbot, Dotbot would still be the lowest.
Nice one! Thanks for the update, Russ!
I crawled most Quantcast top (US) websites and counted bot mentions, disallow all, allow all, crawl-delay, disallow partial, allow partial in robots.txt:
Bot name: mentions, disallow all, allow all, crawl-delay, disallow partial, allow partial
*: 403417, 13381, 27914, 44290, 328892, 130352
mj12bot: 23325, 12102, 38, 9070, 292, 29
googlebot: 22021, 185, 2862, 1926, 11798, 2490
baiduspider: 15875, 9839, 116, 1207, 1989, 145
bingbot: 13026, 1147, 1649, 8165, 5572, 1474
yandexbot: 11850, 7786, 302, 1396, 1958, 1060
msnbot: 11423, 1366, 557, 6486, 4059, 327
ia_archiver: 11157, 5512, 244, 765, 1255, 92
ahrefsbot: 9829, 7644, 32, 723, 190, 11
slurp: 9668, 1698, 568, 4372, 3887, 228
dotbot: 7188, 5838, 13, 221, 177, 4
twitterbot: 6221, 81, 1268, 234, 458, 764
sogou: 6052, 3799, 21, 66, 1336, 14
spbot: 4901, 4288, 0, 178, 36, 2
semrushbot: 4877, 3369, 33, 275, 101, 9
rogerbot: 4788, 2145, 989, 1325, 1226, 42
blexbot: 4538, 4031, 0, 174, 61, 3
sistrix: 3535, 3302, 1, 10, 13, 0
exabot: 3302, 2636, 11, 87, 54, 10
gigabot: 3200, 2164, 23, 196, 59, 3
bubing: 2796, 2475, 0, 5, 17, 1
sitebot: 2723, 2522, 0, 1, 6, 1
seznambot: 2574, 975, 12, 43, 1303, 17
ccbot: 2560, 2086, 13, 122, 52, 17
ezooms: 2381, 2216, 0, 10, 13, 0
archive.org_bot: 2292, 382, 1076, 731, 1747, 19
megaindex: 2074, 1567, 0, 22, 19, 0
voilabot: 1312, 1219, 5, 31, 23, 1
yetibot: 1274, 19, 0, 7, 1238, 0
seokicks-robot: 1125, 1000, 0, 18, 5, 1
mail.ru_bot: 971, 653, 4, 73, 98, 50
facebookexternalhit: 695, 36, 139, 64,, 210, 239
siteexplorer: 639, 587, 0, 3, 4, 0
xovibot: 600, 494, 1, 23, 26, 0
wotbox: 597, 520, 0, 4, 9, 0
linkdexbot: 564, 379, 0, 10, 2, 0
360spider: 534, 381, 8, 23, 34, 7
obot: 534, 319, 0, 0, 0, 0
applebot: 530, 83, 34, 206, 134, 59
vagabondo: 528, 348, 0, 1, 2, 0
searchmetricsbot: 503, 376, 6, 7, 23, 4
meanpathbot: 403, 353, 0, 0, 0, 0
mauibot: 370, 340, 1, 1, 10, 0
linkpadbot: 292, 206, 0, 3, 0, 0
mojeekbot: 277, 214, 0, 3, 1, 0
nerdybot: 244, 196, 0, 2, 0, 0
yacybot: 206, 122, 0, 3, 4, 0
findxbot: 150, 61, 0, 2, 0, 0
extlinksbot: 114, 101, 0, 1, 0, 0
dataprovider: 29, 20, 0, 0, 7, 0
Awesome!
DotBot. The Bot we have crawled the web with for a decade now.
Glad to see the Moz Link Explorer leading with the "closest to Googlebot" data. This just made me like the Moz Link Explorer more than I already do. Thanks for sharing your data on this Russ!
Solid research and comparisons to Ahrefs (what we have typically used) and Majestic. I definitely agree with utilizing multiple link analysis sites to discover the most referring domains, and I was excited to see Moz be the closest to GoogleBot on all 3 data analysis charts your shared.
Great post. Really the article is informative and have helpful SEO strategy that is very important a seo learner. Thanks a lot Russ Jones, for sharing a important topics with us.
The way people on Moz research and provides the amount of information about each and every topic is really great , the above blog is having such a detailed information about robots.txt is very useful.
Er, why not simply only check robots.txt rules for Google bots and follow those instead of the rules set for your own bots?
Simple respect for webmasters. Bots can cause problems like slow down the site or increase bandwidth costs. If a webmaster says don't crawl, we wont.
Very respectful behaviour. Nice!
It is very important to save time to the robot, google compensates it as soon as possible to see the whole robot much better for the page, so it is crucial to tell him where to go and where not.
I allow everything on my robots.txt
Buen post Russ!
It seems very important to pay attention to the status of our website through robots.txt, this helps us to have a "clean" URL and there are many people, even professionals in the sector who do not pay the attention it deserves and also we can assume a small point of improvement in our positioning as Google sees a "clean" site and takes it into account in some of its algorithms.
With these contributions it is much easier to move forward with our SEO projects. Thank you very much Russ
Omg so much information about robots.txt and blocking site. Just few second before i only know how to submit robots.txt to webmaster. Thanks for such valuable info
Definitely not what I was expecting based on the title of this post. I was expecting to read an article related to what your sites robots.txt file should contain based on industry/Google changes. Nonetheless, interesting research, does the job of lending more credibility to Moz Link Explorer at least in the short term.
Russ,
Solid research here man for sure. Forgive me for the brute question - but was this article intended to be a jab at your competitors? As Cyrus pointed out - it's likely that DotBot will eventually get blocked just as much as Ahrefs and Majestic in the future, especially as the crawler becomes more aggressive. Crawl speed obviously has a lot to do with it, and as you mentioned, "crawl politeness" will be enforced. But as an in-house SEO, is there an actionable takeaway from all this?
- Gaetano
Hi Gaetano!
I think the most obvious and immediately actionable takeaway for any SEO comes right at the beginning of the post -
"small changes in robots.txt which prevent some bots and allow others ultimately leads to very different results compared to what Google actually sees."
In a world where we all feel justified in demanding greater and greater accuracy from the tools at our disposal, the lesson we need to take from this is that we should think carefully about the effect our robots.txt directives will have on those tools and the data they can give us.
Interesting also to see that the most pervasive method encountered by all of the tools is "a blanket dismissal of all bots except major search engines - ie: block all and explicitly allow google, bing, yahoo, baidu, etc.". Some might say this is the smart option. Others might call it the lazy one.
Certainly if we choose to invest in using specific tools because we value accurate data we should at least be sure we're not blocking them from our own sites. ;)
- Sha
Let me start with the easy question: as an in-house SEO, is there an actionable takeaway from all this?
If you want all the links, you have to use all the tools. If you want to just use one tool that is most like Google in terms of constituent pages. Using both this analysis and the research I posted here, Moz is the tool for you.
As for whether it was intended to be a crack against our competitors, I certainly intended to draw a distinction between Moz's index and theirs, and that distinction is positive for Moz. The data is freely available for anyone to test. Just go download the Quantcast Top Million list, grab their robots.txt, and use any one of the many free robots.txt testers on github to see for yourself.
First, I originally ran this study in July of 2016. I didn't report on it then even though I could have. The ratios were approximately the same then as now.
Second, I think people need to know about the quality of the data they receive. Our competitors brag about their size (and now Moz does too), and we need to be honest about the impact crawling has on webmasters. If Ahrefs or Majestic wants to run the analysis again next year and show that we have caught up, by all means, they can.
I'm sorry if it hurts the feelings of our competitors when I present research that shows our data is better, but I'm not going to hide solid research just for those purposes.
Russ again a nice research but only accurate for robots.txt blocks, many webmasters and hosting providers use temporary IP blocks after some requests or permanent IP blocks for known unwanted crawler IP ranges at network or web server software level, both are not to test for other bots without spoofing IP addresses (if possible). There are also many websites and hosting providers who block crawler user agents at network or web server software level what you can test by spoofing user agents or compare homepage request timeouts with your Dotbot user agent compared to a web browser user agent.
I agree MOZ crawl mostly nice so far, that can indeed help, but also that MOZ used user agent Ezooms from 2011 till 2014. How much is that user agent blocked and do you still respect it?
"I agree MOZ crawl mostly nice so far, that can indeed help, but also that MOZ used user agent Ezooms from 2011 till 2014. How much is that user agent blocked and do you still respect it?"
Russ,
is it true? Could you please share history of User Agents used by Moz crawlers in the past?
Im looking into Ezooms right now - news to me. We were crawling with DotBot back then but we did apparently have an alias. I did just re-run the analysis and adding in ezooms and the trends still stand. If we assume everyone blocking RogerBot (our site audit crawler), Ezooms (a temporary alias) or DotBot, Moz still comes well below Ahrefs and majestic
All Moz Crawlers, even RogerBot: 7641
Ahrefs: 8423
Majestic: 15740
It appears Ezooms was an alias. I dont know what % of the crawl was powered by it. I can say this though - even if we assume all RogerBot blocks were intended for the web crawler and not our site audit, and we include ezooms bot, and we include Dotbot, Moz is still the least blocked.
Sites from random sample:
All Moz Crawlers, even RogerBot: 7641
Ahrefs: 8423
Majestic: 15740
As for "many webmasters and hosting providers...", I think robots.txt is by far the most prevalent method of blocking individual bots. But it would make for interesting research. Perhaps that might be something you might want to do.
Did you also count Ahrefs old user agent SiteBot used in 2010-2011?
No I did not.
Cool! So what you're saying is that Ahrefs got blocked ~10% more than Moz while crawling ~10x faster for the past few years? :)
Really interesting article - I would love to know DailyMail blocks Ahrefs and not Majestic or Moz.
Agree with what Cyrus said above about the other bots being more active so thats why they are got blocked - more likely to appear in top 'x' most active bots.
My other theory wouldn't really matter for this as its the top 1 million websites, but "black hatters" are more likely to block Ahrefs from their PBN network - as its their preferred choice of tool when doing link analysis and they don't want to give away to the competition their PBN network.
The dailymail.co.uk exclusively blocks Ahrefs. They even do it TWICE in robots.txt...
https://www.dailymail.co.uk/robots.txt
Also, you are right that aggressive crawlers are more likely to trigger a block from a webmaster. This is why crawl politeness is so important. Backlink indexes need to be careful not to burn too many bridges. Moz was able to become comparable in size to Ahrefs and Majestic WITHOUT running into these problems. We have a high level of crawl politeness which forces us to crawl wider rather than deeper sometimes, but in the end it produces a more complete link graph, in my opinion.
> Moz was able to become comparable in size to Ahrefs and Majestic WITHOUT running into these problems.
Russ, don't you think you're misleading people by saying that?
Didn't you increase your crawl speed not too long ago? While Ahrefs is already known to have second most active bot after Google: https://www.incapsula.com/blog/most-active-good-bo...
As for "crawl politeness" - believe me, here at Ahrefs we know a thing or two about it. I'm sure in a year from now we'll see if you guys will be able to catch up with our crawl speed/efficiency/politeness ;)
Thanks for your response.
We have made no adjustments to politeness and we last increased our crawlers was about a year and a half ago. I ran this same analysis about 2 years ago and the ratios are roughly still the same.
I'm sure that Ahrefs knows quite a bit about "crawl politeness" and I didn't seem to imply otherwise. But you are the 2nd or 3rd most pervasive crawler on the web - that comes with both costs and benefits. Today, I outlined the costs, as Ahrefs has certainly touted the benefits (your index size) for many years.
With regard to politeness, it is a gut call - frequency of recrawl, depth of crawl, time between requests, etc. all must be balanced against the threat of being blocked. Indexes have to make a choice. it is similar to whether you decide to keep spam in your index or not. It is both a positive if you want to help webmasters find bad links, but a negative both in costs and in presenting users an accurate reflection of what Google might be judging them on.
I'm just trying to open the eyes of our readers to the complexities of crawling the web and how it influences link indexes differently.
Very good post It will undoubtedly help us to know how to track more and better.
For most of my sites I take the block all and let the ones through that might send me some traffic approach. The problem with the likes of Ahrefs, Majestic, Moz and others is that for a small business I can't justify the cost of using them, and the free offerings are of little use. Hence why would I let them bot my servers for so little in return?
It is a fair question. I think Majestic still offers Open Access to crawl data for your site if you authenticate that you are the site owner. I think Moz should do something similar.
Thanks for that Russ I'll check out Majestic.
The Majestic offering exists for site owners, but it only allows you to see what reports are available, without giving you access to any useful data, so worthless.
I'm surprised that webmasters aren't more proactive on this and block all of the main indexing bots, such as Ahrefs, Majestic, Moz and a few others. Their sole purpose is to harvest as much data about your own sites, and the relationships you have with other sites, and then to sell that data back to the owner and more importantly to your competitors. Sure there's added value with all of the reporting, analysis and aggregation etc. so there's a price, if your site's can justify it. But, even if I was using any of these services, I would still block all of the others (that my competitors may be using) and even the one I'm using too, assuming that's feasible.
The way things are going I can see the day when even Googlebot should be blocked; after all, what's the point of being listed on Google if that doesn't translate into them providing something in return, ie. some free traffic.
All of these analytics companies are relying totally on Webmasters allowing them free access to their properties, but increasingly it's time to ask why.
I just checked how much bots hit four small websites by analyzing their log files.
Period: Jan 1, 2018 till May 24, 2018
Website, A, B, C, D
Web pages, 1, 1, 8, 11
Human hits, 576, 803, 3893, 7205
Bot hits, A, B, C, D:
bingbot, 249, 472, 766, 1709
yandexbot, 413, 238, 494, 1974
mj12bot, 45, 48, 404, 2159
semrushbot, 299, 146, 536, 1221
baiduspider, 93, 194, 771, 879
googlebot, 133, 218, 312, 932
dotbot, 19, 11, 344, 561
360spider, 0, 277, 231, 169
sogou web spider, 181, 301, 184, 1
ahrefsbot, 0, 57, 153, 246
spbot, 39, 26, 134, 252
bubing, 0, 2, 116, 145
mauibot, 0, 16, 135, 99
linkdexbot, 0, 0, 81, 133
seznambot, 24, 0, 103, 26
seokicks-robot, 0, 0, 0, 151
mail.ru_bot, 20, 16, 28, 80
blexbot, 0, 26, 74, 36
dataprovider, 24, 20, 65, 17
extlinksbot, 0, 0, 87, 22
siteexplorer, 0, 0, 48, 38
slurp, 0, 7, 32, 40
exabot, 0, 12, 8, 52
megaindex, 2, 21, 18, 20
netcraft, 9, 10, 7, 32
archive.org_bot , 8, 1, 8, 38
ccbot, 2, 10, 6, 29
obot, 0, 0, 0, 38
yetibot, 0, 7, 0, 18
I don't think bots have any impact by small websites at hardware or traffic cost, an average $3-$5 a month cloud hosting can handle hundred thousand requests a day and have a 10-20TB traffic limit.
Also most bots support crawler delay in robots.txt or you block pages who are to heavy to load often.
Not seen by advertisers, buyers or not listed in search engines (or their API's) can have much more impact.
I expect major search engine bots generate more traffic then backlink tool bots who only request html files. Major search engine bots crawl also media files like css, js, jpg, gif, png, bmp, pdf, doc, xls, ods, avi, mp4 etc.
You must ask yourself if you want a link from a website who block all major backlink tool bots.
Setting a crawl delay is not always a good idea. A popular e-commerce software provider host round 600,000 client websites at only two IP addresses. Most bots limit themselves to maximum one request a second to one unique IP, that's maximum 86,400 requests a day to one unique IP. To crawl that 600,000 websites 150-200 pages deep can take till 2 years and with crawl delay at 10 even till 20 years.
Some interesting research you have on your hands and it definitely shines a good light on the new Link Explorer tool. Cheers.
Keep doing that and crawling more sites! We need better info to make better choices, so we count on you to get them for us! Thanks for the transparecncy at this article!
Excellent contribution!!!
I think it is important to take into account these actions for SEO, taking into account that there are few who actually work with SEO, I have seen that most of them only focus on creating content, but do not spend time to analyze your page and the errors that it has.
For what I consider this information very useful.
Thanks for the input.
Pardon if I overlooked this point of clarity - when you say "Moz's robots.txt profile was most similar to that of Google's," does that mean in quantity only, or in actual, specific domains that block or allow the Moz and Google crawlers as well?
Both statements are true. Relative to Ahrefs and Majestic, DotBot is excluded by fewer sites and we we have fewer examples where Google is not blocked and we are.
Hrefs sucks.... very much better and intuitive MOZ tools, i tried the two platforms and finally take MOZ.
Great Post, Thx Russ.