

While search engine representatives and light hatters (the whitest of the white hatters) say that having great, link-worthy content and links is enough to get high rankings, there are many sites with these traits that do not get listed for the words that matter (the ones that send serious traffic). If it were so easy and every page that deserved a high ranking had it, there would be no need for us -- SEOs. 
The reality is that search engines are far from perfect. They face significant challenges trying to decipher our intentions and find the pages that best match our queries.
Here are some of the reasons why search engines don't return 100% relevant results all the time:
1. Relevance is subjective. This is the biggest problem. You can do a search for 'coffee' in Canada and find Tim Horton's website as the most relevant. Makes sense, as that’s the most popular coffee chain in Canada, but for somebody in Seattle, Starbucks might be the most relevant result. You can do a search for the ‘49ers’ and be looking for the football team, but a historian may be looking for research material on California. And you might even do a search today for 'bones' trying to find where to buy your dog a treat, but tomorrow you do that same search looking for an episode of the TV series 'Bones' that you missed the night before.
How can a search engine disambiguate such searches? Mind reading would be an excellent approach :-)
So far the best approaches the search engines have come up with are the use of human quality raters and personalized search. The better the search engines profile the searcher, the higher the chances of producing relevant results. This method obviously raises a lot of privacy concerns.
2. Natural language searches. A MySQL database engine can precisely return all the relevant records given a query 'select first, last from employee where last = "Smith";'. There is a formal syntax and no ambiguity. A search engine, on the other hand, receives 'who has smith as last name in chicago' or 'smith last name chicago'. The query is in natural language -- our language. There are many different ways to say the same thing--there is context, there are human idiosyncrasies, and so on. The searcher component of a search engine must disambiguate the query and translate it into a more formal manner before looking it up in the index.
3. Poor queries. Many searchers don't know how to express what they want in the real world, and are even worse when attempting to ask a search engine. They call the vacuum cleaner a ‘sucker’ and are unable to find cleaning services online. Worse yet they misspell words, making the problem more 'interesting' for search engines.
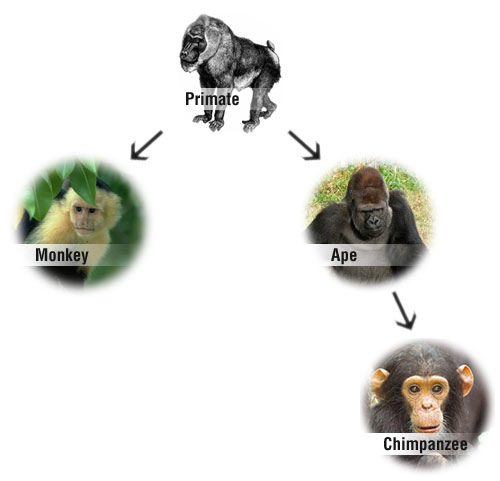
4. Synonymy. This is another challenge. There are words that have the same meaning, like ‘car’ and ‘automobile’. When you do a search you would like to get pages that contain your exact words, and pages that contain other words that mean the same thing, as long as they are relevant to your search. Let’s say you do a search for 'monkey'. You would want your results to include pages that contain monkey, but perhaps also the words ‘chimpanzee’ or ‘ape’. If you were a little bit more strict, you would not want to include pages that say chimpanzee because, although a chimpanzee is a primate, it is not a monkey. These details don’t pass through the minds of most searchers, but search engines have a hard time because of it.
5. Polysemy. There are words that change their meaning depending on the context in which they are used. For example, if you do a search for 'wood' you might want pages that are talking about pieces of a tree, or you might be talking about the geographical area that has many trees. Without the right context, it is hard for a human to tell. Imagine how hard it is for a search engine!
6. Imperfect performance. To follow up on my previous post about relevance feedback, let me introduce a couple of related concepts to better explain this problem: precision and recall.
Precision and recall are metrics used by information retrieval researchers to evaluate the performance of search engines. It doesn't matter how sophisticated the ranking algorithm is, at the end of the day what really matters is whether the user likes the results or not. Precision is a measure of how efficient the search engine is in returning only the relevant results for the search. The more irrelevant results, the lower the precision. Recall, on the other hand, measures how good the search engine is in returning all the relevant results. (Of course, this assumes the researcher knows how many relevant results there are.) The more relevant results missing from the search, the lower the recall.
Ideally, a search engine should identify all relevant documents without returning any irrelevant ones (100% precision and 100% recall). In practice, this has been proven to be impossible, as precision and recall are inversely proportional.
Empirical studies of retrieval performance have shown a tendency for Precision to decline as Recall increases. Trade-off between precision and recall
Fortunately, most searchers are more concerned about precision, especially in the top ten results. Few of us search past the first couple of result pages (SERPs). Relevance feedback via Quality raters is an excellent approach to improve precision. Quality raters can select the documents that are most relevant to the search, and that information can be used to refine the original search and yield better results for most users.
7. Spam. Search engines identify relevant pages by means of 'quality signals' or metrics that can be deduced from web pages by automated means. The challenge to search engines is that once black hat SEOs identify those signals, they can start to fake them. I think that over time it is going to be harder and harder to fake quality signals, but it is never going to be impossible. For humans it is easy to spot spam, but for computers it is much harder.
Why is it important to know all this?
This subject is important because it proves an interesting point. Although the search engines don't want to admit it, they need us (SEOs). As I mentioned above, relevance is subjective. Do you want to take a passive approach and hope for the Quality raters to qualify your website for the searches they think are relevant? Or, instead, do you want to take an active role and identify the best keywords, include them in your content and incoming links, and carefully study websites that are ranking high (web authorities) to see how you can do the same? Personally, I prefer the active role.
This is a great post, Hamlet. When I first read it on Youmoz, I thought, "This deserves to be promoted!" Glad it was.
Some thoughts I had about this subject:
The English language is deeper and more complicated than most other languages. We have more synomyms, homonyms, and related terms than other languages. It's also much more elastic than other languages, which means that new words are created and assimilated to a greater degree than other languages.
It's often said that English is the best language for writing (especially poetry) because the incredibly rich vocabulary allows for varied word choice that gives depth and nuance that other languages might not.
Funny how these attributes - which make English such an expressive language - account for most of the problems you listed. In other words, search engines are fighting an uphill battle because of the very things that make English (and language in general) so wonderful. (I'm sure search isn't perfect in other countries either; it's just probably even more complicated in English).
I wonder though, as someone did earlier: as the search engines grow and change to better interpret language, will people do the same? Will the average person someday understand that if they want to search for a forest, it's better not to use "wood"? Will humans contribute to the search engine problem and meet Google halfway? We shouldn't expect them to do all the work, after all...
lorisa - thanks for your kind words. I felt like I was reading poetry. Was that on purpose? ;-)
Spanish is my first language and many things you said about English are also true for Spanish. I guess the same could be said about other languages. I have to agree with you that English is definitely better in the sense that you can say more with fewer words (which is something that I am still trying to learn as an ESL writer).
I wouldn't rule out that possibility.
Thanks for the compliment, Hamlet! You're a real prince!*
It seems to me that search is contingent on three things: the search engine itself, the searcher, and the language used for search. Search engines can refine themselves for the next century, but I don't think they'll ever be able to completely predict the other two parts of the equation.
*I've wanted to say that for awhile...I love Shakespeare, and your namesake is my favorite play =)
Thanks for the compliment too! I am ashamed to admit that I have not read the book yet :-(. I guess it is about time!
That is why the Quality raters have become a very important part of modern search engines.
I would not be surprised if the number of quality raters increased an order of magnitude (from 10,000 to 100,000) in the next few years.
Oh, you must read it! But, as with all of Shakespeare's plays, it's better seen than read.
Good to know that the human component can't ever be taken out of the search equation completely!
I followed your advice and pre-ordered the two-disc DVD. I'm going to be or not to be watching it very soon :-)
This post was timed really well - only yesterday a friend asked me why the search results they want are usually towards the bottom-end of the top 10 or in some cases buried much deeper in the serps.
I pretty-much explained the points you made, although there were a couple I missed so I'll forward them on...
For more commonly searched-for terms, the results often aren't too bad (and are improved further if you use Distilled's wiki removal plug-in)... but for more niche terms you can end-up having to wade-through a lot of long-tail, affiliate sites, random blogs etc. to find what you're after.
In the end, no search engine will ever be perfect (or at least not for a very long time) so it's great that objective posts like this pop-up from time-to-time to remind us of this.
Nice article Hamlet
SiteMost,
Thanks, I am glad you enjoyed the post.
Google doesn't agree with you. They want to build the perfect search engine by 2012.
Meh - who really wants Google to agree with them? If Google agreed with everything I said I'd be out of a job...
If they do make the perfect search engine by 2012, I won't be complaining... although it reminds me of old movies and news clippings that would look into the future - by now we should be wearing silver Lycra body-suits and going to work in flying cars...
A perfect search engine would be great - but I'd rather a jet pack.
Hamlet - excellent post - just a quick piece - Dr. Garcia (an IR researcher in California) blogged about his disagreement with the mention of LSI in this piece.
I apologize most deeply and humbly for any confusion I might have inadvertently helped to propagate.
Reading Dr. Garcia's post, the disagreement seems to be the association between LSI and synonymy. Take a look at his tutorial on LSI, especially the section "Another SEO Myth..."
If I'm reading this tutorial correctly (and please, by all means cut off my head that I stuck out earlier!), he sums his argument up by saying, "synomyns are a special class of tokens that do not tend to occur together, but tend to co-occur in similar contexts (neighboring terms)[...] The reverse is not necessarily true; not all terms with a second-order co-occurrence relationship are synonyms."
So when I said "synonyms" earlier I was using the term incorrectly. I was trying (unsuccessfully!) to get at the idea that if you're looking for information on "primates", documents which never mention the term "primate", but do mention "chimpanzee", "ape", and "monkey" could be very useful. These terms are not synonyms for "primate".
I've submitted such a correction to Dr. Garcia, and I shall report back to you gracious Mozzers if my correction is, in fact, correct.
After having sync'd up with Dr. Garcia here's the lowdown.
The problem with my above comment is that I said "synonym" when I should have said "related terms, not necessarily synonyms". Moreover, by saying "synonym" I was helping to perpetuate the "Synonym Fallacy", under which people incorrectly conclude that LSI clusters terms because they are synonyms. This is not the case.
Moral of the story: use language precisely or else people will draw the wrong conclusions about what you say.
Nick - thanks for making it clearer.
Rand - Thanks for promoting my post. That was unexpected.
Please note that as Nick acknowledges, I did not mention LSI on my post and I trusted Nick's assertions --he is the one with formal IR education.
I am learning IR by reading books (I'm not done with the LSI one yet), so I have to respect and accept what Dr. Garcia and the IR experts say.
I try to research carefully what I write to avoid spreading myths. I apologize for any confusion.
BTW: Two out of three of my posts have been promoted. For an ESL blogger that is not bad. I think others ESL readers should be encouraged to post :-)
A sharp editor helps a lot ;-)
Hamlet - you've got Rebecca to thank here, not me. She's our official YOUmoz editor, promoter, etc. :)
Gracias Rebecca!
You never said if you liked the monkey pictures :-)
Very good points. Particularly polysemy. I've not run into it myself, but it is a great point.
I have had the issue with "automobile" and "car" and had to come up with multiple version of the content (still very different from each other) .
Thanks, Brian. Search engines still face significant problems. We should have food on our tables for a while ;-)
I'm glad this was promoted, this is is an excellent post
thanks, Matt
Nice post Hamlet. Especially the short section about spam. Really nice way of explaining it.
Also, thanks for the primate diagram and introducing me to the word "disambiguate". :-)
Campy - Glad you liked it
gotta love the monkey references!
Yes. I used the monkeys to make the post more entertaining :-)
Good post Hamlet - also, the number (and quality) of comments provide almost as much value as the original article. I still find it quite remarkable that about 20% of queries at Google are being seen by them for the first time - but given the complexity of language, and the innate creativity and unpredictability of the human mind, there is likely to always be a significant percentage of queries that fall into this category.
Thanks, podcomplex.
I agree
Hi Hamlet,
Thanks for such a thought-provoking post; I used it as the basis for a post myself today. Your reader who comments about timeliness and freshness had an excellent point. I imagine that search engines face still more challenges we haven't discussed.
I also appreciate what you say about many of the problems coming from the searchers themselves rather than incomplete algorithms.
Search engines deserve a round of applause for accepting that it is unlikely for users to become universally educated in a consistent search syntax, and getting on with the business of attempting to disambiguate cryptic and minimalist queries.
Looking forward to your next post!
I agree.
Thanks, I'll try to make the next one even better.
hi all - i am currently building a localised search engine for Dundee in Scotland. I am working on how the search terms will be relevant to the viewers search terms. I am just now resticted to the company name, address and the search term that i enter into the search column relating to the company. i have around 3k results just now but i am building the list hopfull up to around 20 k in the next month. my mini search engine is for dundee will be for people looking for businesses in dundee and i am trying to make the search rsults more relevant to the terms the people are typing. i am using sql tersm just now but sometimes the things that people get shon have nothing to do with the terms they type in simply because the data base is returning what it thinks is best accoring to the beasi nfo it has to work with .. this is pretty crappy just now but i have noticed that when people are using my search engine they are still getting mostly 50% of the results they would like... my next step is to make things more in tune with what people want. i am thinking about writing a scritp that will analize peoples web site to see if they have the keyphrases the viewer is tpying and returning results according to the content of their sites and shuving the peoples results who have no website to show to the bottom of the listings ... this in turn will give the people with webites an advantage over the listings that dont .. this might be good or bad .. but i would say that the companies in my are that have a website that can be analised by me and graded according to the content is better than a company that has no site at all.. time will tell
I think there's an 8th here Hamlet: Timeliness and Freshness.
Trends in query use and meaning rise and fall all the time. What was perfectly relevant yesterday for a query can be absolutely irrelevant tomorrow due to a major event or change in the word meaning. But once that event is no longer "newsworthy" the original content can then become the more relevant content for a query.
Example: London Tube - in the events leading up to the tube bombings of a couple of years ago, the content you'd expect to see should be tube maps and timetables. Immediately after the event and for a few months afterwards the content should have been about the bombings. But then it reverts back again.
This is a fairly obvious example, but as an ex relevancy manager and spam cleaner for a search engine, I can say that there are much more subtle queries for which this switching in meaning is not so clear cut, and sometimes it's very difficult to determine the predominant meaning and react as quickly as that meaning changes in search queries.
Natewood - That is an excellent addition.
Google made that problem public on the New York Times article: Google Keeps Tweaking Its Search Engine
They say they are addressing the problem with something they call QDF (Query Deserves Freshness)
What I really like about the comments so far is that SEOs and search engine experts agree that search engines are still far from producing 100% relevant results.
Do you think they will ever do?
Sometimes I spend more time to click throught all the links provided by the search engines than reading the actual informaiton I'm looking for which is frustrating. This happens only if I don't know for what to look, what keywords to use to get the desired results.
May be you should then try using google suggest , though a old feature now, which can save your time when you are confused about the search keywords.
https://www.google.com/webhp?complete=1&hl=en
Other way you are giving all those websites extra referrars ;)
Thanks . . . I'll keep that in mind for my upcoming researches where I'll be confused :D
The referrals . . . I saw a very funny referral from ask.com the other day. Somebody entered "what was the music playlists in australia 2000" into ask.com and for ths my website's result number one, but for what . . . for mentioning the word "Australia" and "Music" and since this website is about playlists and theword playlist is in the website title I got hit, well I guess that's why my site's listed first for this request.
I would say that ask.com didn't understand the question, like i didn't cos there's something missing. For what or from what was this playlist the person was looking for? I don't know, but I guess it was the Essential mix playlist from New Years eve at Bondi Beach, Sydney Australia, but this is what I would have searched for since I don't know any other music playlist for that time from down under. Anyway . . . this search shows somewow how search will show what they know and if the user doesn't know how to aks, then the result won't be that great aswell, but like I said in my previous post, thngs like that happen to me aswell, so we need to be specific.
Thats just not with ask.com, google also shows results based on keyword combinations in a website when a long query is made instead of single keywords.
This is the reason blogs get more traffic because of the combination of keywords from the blog posts and categories based keywords.
Thanks for the great points. You may find a book called "Ambient Findability" by Peter Morville interesting. After reading it you may find yourself convinced that search engines and search as we know it are only in the earliest stages of development and well on our way to "complete navigability".
Some sections are a little dry but all search engine marketers can benefit from knowing a little "information retrieval theory".
acm.miller,
Thanks a lot for the book. Looks like a interesting read. I just bought it.
I am currently reading: Understanding Search Engines, Mathematical Modeling and Text Retrieval (Second Edition) by Michael W. Berry and Murray Browne. The book does an excellent coverage of the main concepts and the math is easy to follow if you have undergraduate math skills. I plan to post a review on my blog.
Many SEOs would wonder why it is important to keep learning about the search engines. I think it is wise to keep up with their advances, if we want to remain comeptitive in the near future. Their tecnology is going to get far more complex.
The good part is that the user is more and more becoming the center. Make your websites primarily for your visitors, without forgetting the search engines, and should win the long battle.
Wow, great post, lots of good information here. I find it interesting to note that most of what you're saying isn't about what the serarch engines are doing, but rather what the searcher is failing to do.
Should we really be making changes to how the search engines work? Or how the searcher looks? As you say searching for "primate" has its problems, but if the user has some (limited,basi) knowledge and adds those to the search parameters aren't they going to get beeter results?
Shouldn't we be teaching clients to search better as well as pushing for better results?
mercutiom,
Thanks for your comment. You hit the nail on the head. We ARE the main problem search engines face.
Unfortunately it is a bigger task to teach the whole world how to properly use the search engines, than to adapt the search engines to our way of searching. Remember, relational databases are 'perfect' because the DBAs know precisely how to ask the questions. How likely it is that we could train millions to do the same thing?
Google is already working to create the perfect search engine for a reason.
Here in Vancouver it's a real toss up between Tim Horton's and Starbucks, actually I think Starbucks has the edge, ;-)
Linda,
Glad to hear that. In my last visit to Toronto all I could see was Tim Horton's. No Starbucks in sight :-(
This is an excellent post, Hamlet.
So true. I get so frustrated when I see how some of my 'normal' (non-seo) friends search. i used to have races with one friend to see who could find some bit of info first. I'd usually find the answer within the first few results, while they were still sorting through irrelevant pages.
For someone who is an English as a second language blogger, your writing skills are better than a lot of English as a first language bloggers out there. Nice job!
kimber,
Thanks for your kind words.
I have to admit that I cheat. A professional technical writer edits most of my posts ;-) Unfortunately, I write as bad as you read on my comments.
Great Post Hamlet. This is certainly the case in my situation, and also very frustrating. We do very well in Canada - therefore well in the SERP's as well. But we are pushing international and we're not relevant at all there. Most of our links come from pages from Canada, so were working on a link building campaign internationally.
Thanks, Markb. As you correctly said, the key in your case is to get more links from international websites. I'd also create a separate website (.com instead of .ca) for your international efforts.
The clear reason is youtube is owned by google > more preferance
Wikipedia has lot of content leached from webmasters > more preferance even though its worth listing in top or not.
I think some people do make dubious stabs at their search terms -- but I think some may argue that people don't make poor terms, SE's just can't yet handle the robust nature of human language. I hope our expression never becomes homogenized, even if it saves you 30 seconds or 30 minutes..
Bud,
I hope the same. For the look of things, search engines will keep adapting to the searchers inefficiencies.
A couple of notes from theoretical IR (from many years ago, so Google et. al are doing it in some form):
When a site, any site, gets a request (e.g. a query) it knows the originating IP address. This exposes the country of origin, the owning organization, and even the latitude and longitude (I've seen a demo app from Google that uses this info in a fun way). So you don't need personalized search to get personalized service (whether you want it or not).
Latent Semantic Indexing is a relatively old technique to help with Synonymy. I've seen it (and implemented such systems) put to good use. Essentially it looks for how often pairs of words occur in the same documents. We could argue about why this works, but empirically it does.
Nick,
I am glad to have someone with a IR education contributing. Thanks for your comment.
You can get a database that provides such information from ip2location.com. I am subscribed to their service as we use it for some of our web applications (primarily for fraud detection). Thanks for the interesting paper, though.
Please note that physical location is only one of the examples I used to illustrate relevance is subjective. By no means I am implying that the problem is impossible to solve.
Excellent! The book I am currently reading is about LSI. I have to agree with you that LSI can help with synonymy and polysemy, but the problem is that LSI is highly unlikely to be in use in the main search engines, due to their large indexes.
In order to support my claim, let me quote a paragraph from the book: Understanding Search Engines: Mathematical Modeling and Text Retrieval by Michael W. Berry and Murray Browne, Chapter 7, page 77:
Here is the PDF of the referenced paper
Thanks for the deep follow up :)
I agree that a full SVD is not tractable for the web. However, as in a lot of IR , you could hack the problem, do approximations or sampling, etc. and get some of the advantage. Plus there are other advantages to a dimensionality reduction (lower dimension index = less space, better query performance, etc.). If I worked at Google and they weren't not already doing it, I'd by working on LSI for (parts of) their index as a 20% project.
If you're really into IR theory and LSI, see this paper by Dr. Lillian Lee of Cornell Univserity on Iterative Rescaling for LSI. I saw a dumbed down talk on it, and got about 75% of the info. So the paper will hurt your head.
Also, typically LSI won't help with polysemy (there's a good IR midterm question by the way!). In fact, you could make the argument (/me sticks neck out) that LSI hurts polysemy. However, I think (/me extends neck further) polysemy can be naturally addressed (to some extend) by multi word queries.
For example, see the problem in this Google trends programming languages graph. At least when I view it, one of the key news stories is "pet python strangles man". Polysemy has caused us some problems. But the query I'm personally more likely to try is "python programming". I'd wager this won't bring up too many hits about pet pythons (because of the additional 1-word context). In this case the synonymy between "programming", "development", "web development", etc. is going to be the bigger problem.
Hey Nick,
That is some really cool stuff. You and I are going to be really good pals :-) Those papers look really scary. I am working to improve my linear algebra and graph theory skills, they are still undergraduate level.
BTW: I like you post about Amazon EC2, I'd will like to play with it in the near future.
Good post. Sounds like if search engines are ever perfected SEO will be a memory. Might be a while though...
DrDave,
I think it will be a looong while :-)
You are right we should be happy with these irrelevant results :p because thats when people need Seo's
Amit,
That is the point of the whole post. We are needed!
Imagine if we could all band together to use Robots.txt to keep Googlebot from indexing our sites. Then they'd have no content to show people.
Google needs us as much as we need them.
That would be very interesting to see. I think that would be a shocking surprise for them.
They know we need each other and that is why they are more forthcoming lately. More tools, more feedback, etc.