

A lot has changed in the five years since I first wrote about what was Google Webmaster Tools, now named Google Search Console. Google has unleashed significantly more data that promises to be extremely useful for SEOs. Since we’ve long since lost sufficient keyword data in Google Analytics, we’ve come to rely on Search Console more than ever. The “Search Analytics” and “Links to Your Site” sections are two of the top features that did not exist in the old Webmaster Tools.
While we may never be completely satisfied with Google’s tools and may occasionally call their bluffs, they do release some helpful information (from time to time). To their credit, Google has developed more help docs and support resources to aid Search Console users in locating and fixing errors.
Despite the fact that some of this isn’t as fun as creating 10x content or watching which of your keywords have jumped in the rankings, this category of SEO is still extremely important.
Looking at it through Portent’s epic visualization of how Internet marketing pieces fit together, fixing crawl errors in Search Console fits squarely into the "infrastructure" piece:
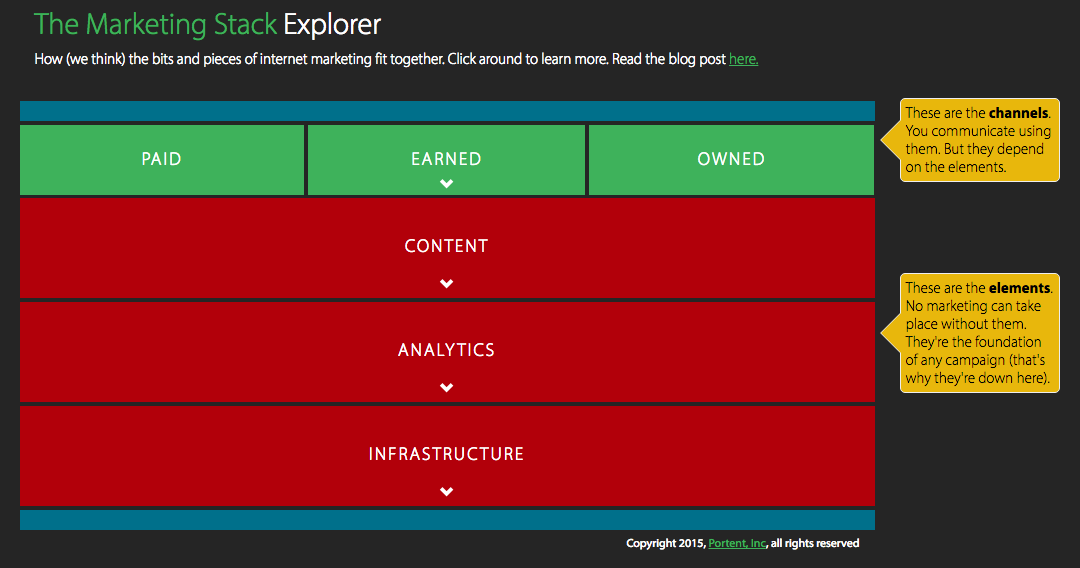
If you can develop good habits and practice preventative maintenance, weekly spot checks on crawl errors will be perfectly adequate to keep them under control. However, if you fully ignore these (pesky) errors, things can quickly go from bad to worse.
Crawl Errors layout
One change that has evolved over the last few years is the layout of the Crawl Errors view within Search Console. Search Console is divided into two main sections: Site Errors and URL Errors.
Categorizing errors in this way is pretty helpful because there’s a distinct difference between errors at the site level and errors at the page level. Site-level issues can be more catastrophic, with the potential to damage your site’s overall usability. URL errors, on the other hand, are specific to individual pages, and are therefore less urgent.
The quickest way to access Crawl Errors is from the dashboard. The main dashboard gives you a quick preview of your site, showing you three of the most important management tools: Crawl Errors, Search Analytics, and Sitemaps.
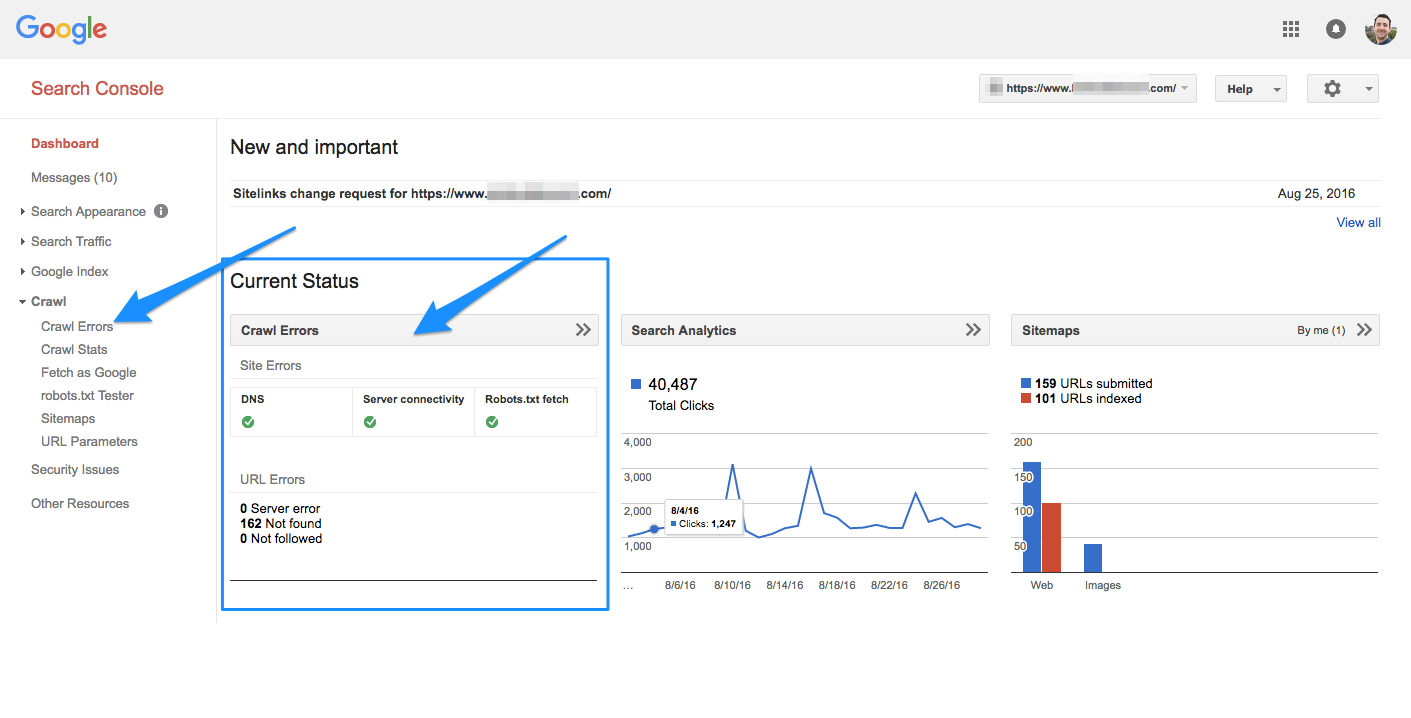
You can get a quick look at your crawl errors from here. Even if you just glance at it daily, you’ll be much further ahead than most site managers.
1. Site Errors
The Site Errors section shows you errors from your website as a whole. These are the high-level errors that affect your site in its entirety, so don’t skip these.
In the Crawl Errors dashboard, Google will show you these errors for the last 90 days.
If you have some type of activity from the last 90 days, your snippet will look like this:
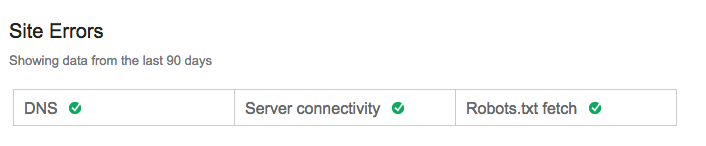
If you’ve been 100% error-free for the last 90 days with nothing to show, it will look like this:
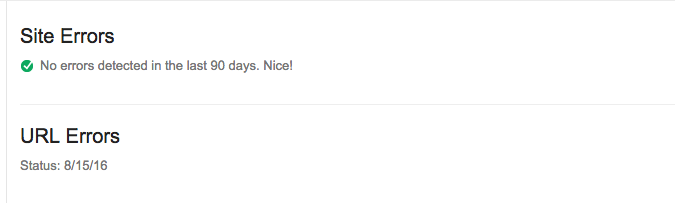
That’s the goal — to get a “Nice!” from Google. As SEOs we don’t often get any validation from Google, so relish this rare moment of love.
How often should you check for site errors?
In an ideal world you would log in daily to make sure there are no problems here. It may get monotonous since most days everything is fine, but wouldn’t you kick yourself if you missed some critical site errors?
At the extreme minimum, you should check at least every 90 days to look for previous errors so you can keep an eye out for them in the future — but frequent, regular checks are best.
We’ll talk about setting up alerts and automating this part later, but just know that this section is critical and you should be 100% error-free in this section every day. There’s no gray area here.
A) DNS Errors
What they mean
DNS errors are important — and the implications for your website if you have severe versions of these errors is huge.
DNS (Domain Name System) errors are the first and most prominent error because if the Googlebot is having DNS issues, it means it can’t connect with your domain via a DNS timeout issue or DNS lookup issue.
Your domain is likely hosted with a common domain company, like Namecheap or GoDaddy, or with your web hosting company. Sometimes your domain is hosted separately from your website hosting company, but other times the same company handles both.
Are they important?
While Google states that many DNS issues still allow Google to connect to your site, if you’re getting a severe DNS issue you should act immediately.
There may be high latency issues that do allow Google to crawl the site, but provide a poor user experience.
A DNS issue is extremely important, as it's the first step in accessing your website. You should take swift and violent action if you’re running into DNS issues that prevent Google from connecting to your site in the first place.
How to fix
- First and foremost, Google recommends using their Fetch as Google tool to view how Googlebot crawls your page. Fetch as Google lives right in Search Console.
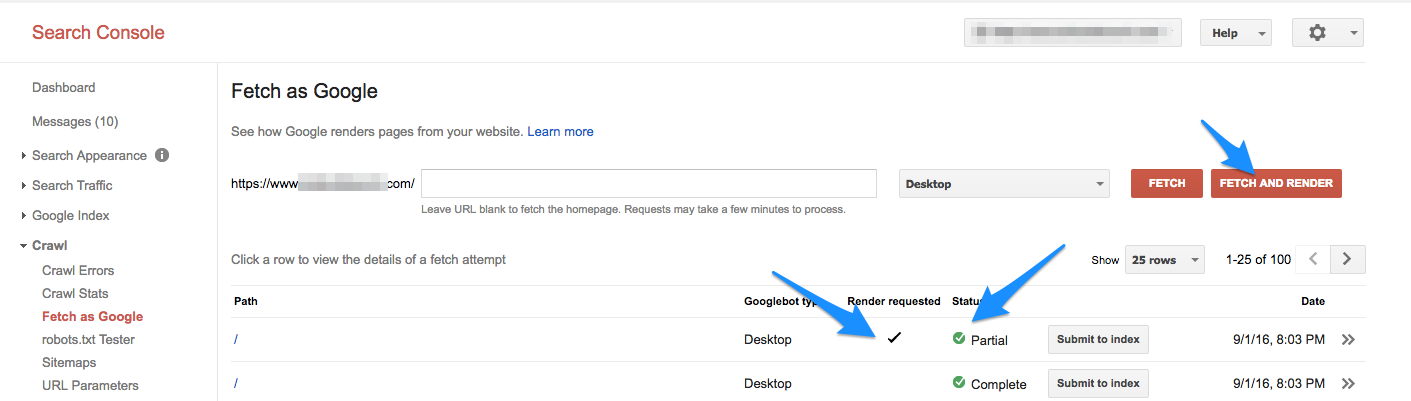
If you’re only looking for the DNS connection status and are trying to act quickly, you can fetch without rendering. The slower process of Fetch and Render is useful, however, to get a side-by-side comparison of how Google sees your site compared to a user. - Check with your DNS provider. If Google can’t fetch and render your page properly, you’ll want to take further action. Check with your DNS provider to see where the issue is. There could be issues on the DNS provider's end, or it could be worse.
- Ensure your server displays a 404 or 500 error code. Instead of having a failed connection, your server should display a 404 (not found) code or a 500 (server error) code. These codes are more accurate than having a DNS error.
Other tools
- ISUP.me – Lets you know instantly if your site is down for everyone, or just on your end.
- Web-Sniffer.net – shows you the current HTTP(s) request and response header. Useful for point #3 above.
B) Server Errors
What they mean
A server error most often means that your server is taking too long to respond, and the request times out. The Googlebot that's trying to crawl your site can only wait a certain amount of time to load your website before it gives up. If it takes too long, the Googlebot will stop trying.
Server errors are different than DNS errors. A DNS error means the Googlebot can’t even lookup your URL because of DNS issues, while server errors mean that although the Googlebot can connect to your site, it can’t load the page because of server errors.
Server errors may happen if your website gets overloaded with too much traffic for the server to handle. To avoid this, make sure your hosting provider can scale up to accommodate sudden bursts of website traffic. Everybody wants their website to go viral, but not everybody is ready!
Are they important?
Like DNS errors, a server error is extremely urgent. It’s a fundamental error, and harms your site overall. You should take immediate action if you see server errors in Search Console for your site.
Making sure the Googlebot can connect to the DNS is an important first step, but you won’t get much further if your website doesn’t actually show up. If you’re running into server errors, the Googlebot won’t be able to find anything to crawl and it will give up after a certain amount of time.
How to fix
In the event that your website is running fine at the time you encounter this error, that may mean there were server errors in the past Though this error may have been resolved for now, you should still make some changes to prevent it from happening again.
This is Google’s official direction for fixing server errors:
“Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly.”
Before you can fix your server errors issue, you need to diagnose specifically which type of server error you’re getting, since there are many types:
- Timeout
- Truncated headers
- Connection reset
- Truncated response
- Connection refused
- Connect failed
- Connect timeout
- No response
Addressing how to fix each of these is beyond the scope of this article, but you should reference Google Search Console help to diagnose specific errors.
C) Robots failure
A Robots failure means that the Googlebot cannot retrieve your robots.txt file, located at [yourdomain.com]/robots.txt.
What they mean
One of the most surprising things about a robots.txt file is that it’s only necessary if you don’t want Google to crawl certain pages.
From Search Console help, Google states:
“You need a robots.txt file only if your site includes content that you don't want search engines to index. If you want search engines to index everything in your site, you don't need a robots.txt file — not even an empty one. If you don't have a robots.txt file, your server will return a 404 when Googlebot requests it, and we will continue to crawl your site. No problem.”
Are they important?
This is a fairly important issue. For smaller, more static websites without many recent changes or new pages, it’s not particularly urgent. But the issue should still be fixed.
If your site is publishing or changing new content daily, however, this is an urgent issue. If the Googlebot cannot load your robots.txt, it’s not crawling your website, and it’s not indexing your new pages and changes.
How to fix
Ensure that your robots.txt file is properly configured. Double-check which pages you’re instructing the Googlebot to not crawl, as all others will be crawled by default. Triple-check the all-powerful line of “Disallow: /” and ensure that line DOES NOT exist unless for some reason you do not want your website to appear in Google search results.
If your file seems to be in order and you’re still receiving errors, use a server header checker tool to see if your file is returning a 200 or 404 error.
What’s interesting about this issue is that it’s better to have no robots.txt at all than to have one that’s improperly configured. If you have none at all, Google will crawl your site as usual. If you have one returning errors, Google will stop crawling until you fix this file.
For being only a few lines of text, the robots.txt file can have catastrophic consequences for your website. Make sure you’re checking it early and often.
2. URL Errors
URL errors are different from site errors because they only affect specific pages on your site, not your website as a whole.
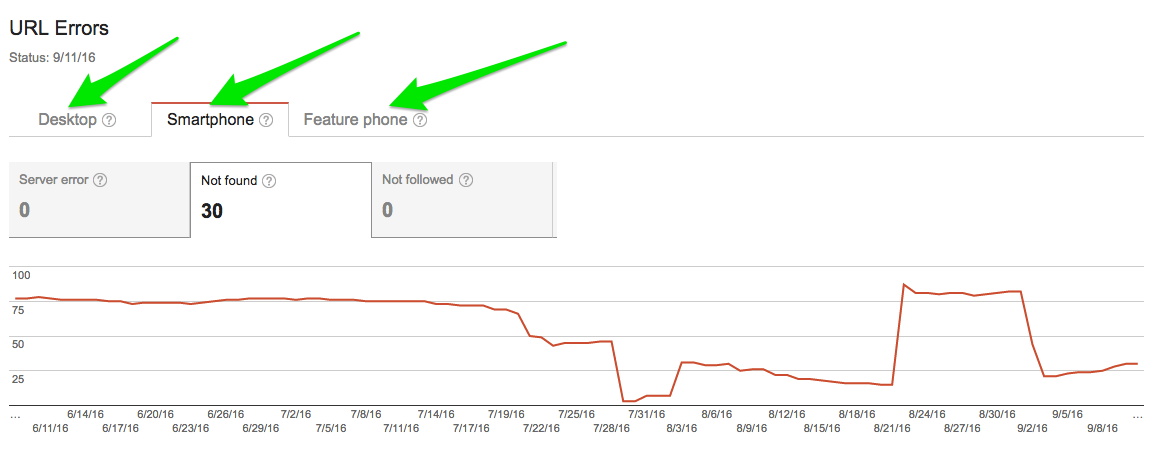
Google Search Console will show you the top URL errors per category — desktop, smartphone, and feature phone. For large sites, this may not be enough data to show all the errors, but for the majority of sites this will capture all known problems.
Tip: Going crazy with the amount of errors? Mark all as fixed.
Many site owners have run into the issue of seeing a large number of URL errors and getting freaked out. The important thing to remember is a) Google ranks the most important errors first and b) some of these errors may already be resolved.
If you’ve made some drastic changes to your site to fix errors, or believe a lot of the URL errors are no longer happening, one tactic to employ is marking all errors as fixed and checking back up on them in a few days.
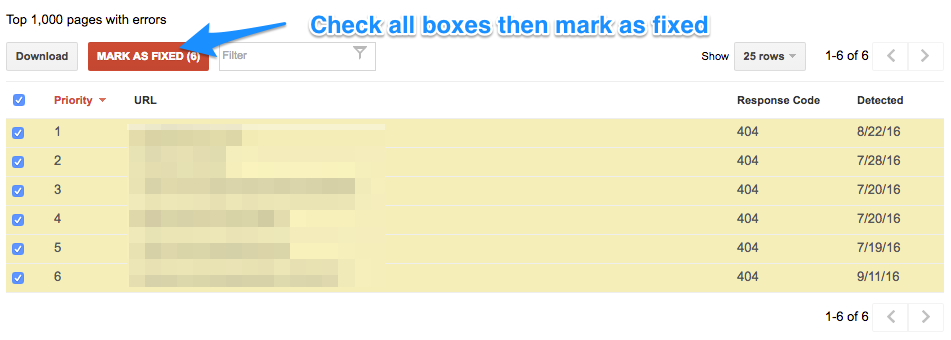
When you do this, your errors will be cleared out of the dashboard for now, but Google will bring the errors back the next time it crawls your site over the next few days. If you had truly fixed these errors in the past, they won’t show up again. If the errors still exist, you’ll know that these are still affecting your site.
A) Soft 404
A soft 404 error is when a page displays as 200 (found) when it should display as 404 (not found).
What they mean
Just because your 404 page looks like a 404 page doesn’t mean it actually is one. The user-visible aspect of a 404 page is the content of the page. The visible message should let users know the page they requested is gone. Often, site owners will have a helpful list of related links the users should visit or a funny 404 response.

The flipside of a 404 page is the crawler-visible response. The header HTTP response code should be 404 (not found) or 410 (gone).
A quick refresher on how HTTP requests and responses look:
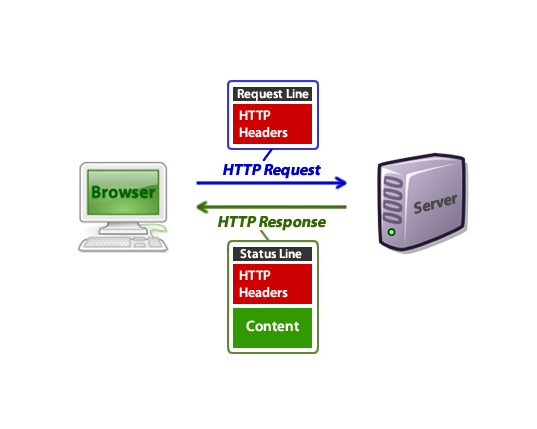
Image source: Tuts Plus
If you're returning a 404 page and it's listed as a Soft 404, it means that the header HTTP response code does not return the 404 (not found) response code. Google recommends “that you always return a 404 (not found) or a 410 (gone) response code in response to a request for a non-existing page.”

Another situation in which soft 404 errors may show up is if you have pages that are 301 redirecting to non-related pages, such as the home page. Google doesn’t seem to explicitly state where the line is drawn on this, only making mention of it in vague terms.
Officially, Google says this about soft 404s:
“Returning a code other than 404 or 410 for a non-existent page (or redirecting users to another page, such as the homepage, instead of returning a 404) can be problematic.”
Although this gives us some direction, it’s unclear when it’s appropriate to redirect an expired page to the home page and when it’s not.
In practice, from my own experience, if you're redirecting large amounts of pages to the home page, Google can interpret those redirected URLs as soft 404s rather than true 301 redirects.
Conversely, if you were to redirect an old page to a closely related page instead, it's unlikely that you'd trigger the soft 404 warning in the same way.
Are they important?
If the pages listed as soft 404 errors aren't critical pages and you're not eating up your crawl budget by having some soft 404 errors, these aren't an urgent item to fix.
If you have crucial pages on your site listed as soft 404s, you’ll want to take action to fix those. Important product, category, or lead gen pages shouldn't be listed as soft 404s if they're live pages. Pay special attention to pages critical to your site’s moneymaking ability.
If you have a large amount of soft 404 errors relative to the total number of pages on your site, you should take swift action. You can be eating up your (precious?) Googlebot crawl budget by allowing these soft 404 errors to exist.
How to fix
For pages that no longer exist:
- Allow to 404 or 410 if the page is gone and receives no significant traffic or links. Ensure that the server header response is 404 or 410, not 200.
- 301 redirect each old page to a relevant, related page on your site.
- Do not redirect broad amounts of dead pages to your home page. They should 404 or be redirected to appropriate similar pages.
For pages that are live pages, and are not supposed to be a soft 404:
- Ensure there is an appropriate amount of content on the page, as thin content may trigger a soft 404 error.
- Ensure the content on your page doesn’t appear to represent a 404 page while serving a 200 response code.
Soft 404s are strange errors. They lead to a lot of confusion because they tend to be a strange hybrid of 404 and normal pages, and what is causing them isn't always clear. Ensure the most critical pages on your site aren't throwing soft 404 errors, and you’re off to a good start!
B) 404
A 404 error means that the Googlebot tried to crawl a page that doesn’t exist on your site. Googlebot finds 404 pages when other sites or pages link to that non-existent page.
What they mean
404 errors are probably the most misunderstood crawl error. Whether it’s an intermediate SEO or the company CEO, the most common reaction is fear and loathing of 404 errors.
Google clearly states in their guidelines:
“Generally, 404 errors don't affect your site's ranking in Google, so you can safely ignore them.”
I’ll be the first to admit that “you can safely ignore them” is a pretty misleading statement for beginners. No — you cannot ignore them if they are 404 errors for crucial pages on your site.
(Google does practice what it preaches, in this regard — going to google.com/searchconsole returns a 404 instead of a helpful redirect to google.com/webmasters)
Distinguishing between times when you can ignore an error and when you’ll need to stay late at the office to fix something comes from deep review and experience, but Rand offered some timeless advice on 404s back in 2009:
“When faced with 404s, my thinking is that unless the page:
A) Receives important links to it from external sources (Google Webmaster Tools is great for this),
B) Is receiving a substantive quantity of visitor traffic, and/or
C) Has an obvious URL that visitors/links intended to reach
It's OK to let it 404.”
The hard work comes in deciding what qualifies as important external links and substantive quantity of traffic for your particular URL on your particular site.
Annie Cushing also prefers Rand’s method, and recommends:
“Two of the most important metrics to look at are backlinks to make sure you don’t lose the most valuable links and total landing page visits in your analytics software. You may have others, like looking at social metrics. Whatever you decide those metrics to be, you want to export them all from your tools du jour and wed them in Excel.”
One other thing to consider not mentioned above is offline marketing campaigns, podcasts, and other media that use memorable tracking URLs. It could be that your new magazine ad doesn’t come out until next month, and the marketing department forgot to tell you about an unimportant-looking URL (example.com/offer-20) that’s about to be plastered in tens thousands of magazines. Another reason for cross-department synergy.
Are they important?
This is probably one of the trickiest and simplest problems of all errors. The vast quantity of 404s that many medium to large sites accumulate is enough to deter action.
404 errors are very urgent if important pages on your site are showing up as 404s. Conversely, like Google says, if a page is long gone and doesn’t meet our quality criteria above, let it be.
As painful as it might be to see hundreds of errors in your Search Console, you just have to ignore them. Unless you get to the root of the problem, they’ll continue showing up.
How to fix 404 errors
If your important page is showing up as a 404 and you don’t want it to be, take these steps:
- Ensure the page is published from your content management system and not in draft mode or deleted.
- Ensure the 404 error URL is the correct page and not another variation.
- Check whether this error shows up on the www vs non-www version of your site and the http vs https version of your site. See Moz canonicalization for more details.
- If you don’t want to revive the page, but want to redirect it to another page, make sure you 301 redirect it to the most appropriate related page.
In short, if your page is dead, make the page live again. If you don’t want that page live, 301 redirect it to the correct page.
How to stop old 404s from showing up in your crawl errors report
If your 404 error URL is meant to be long gone, let it die. Just ignore it, as Google recommends. But to prevent it from showing up in your crawl errors report, you’ll need to do a few more things.
As yet another indication of the power of links, Google will only show the 404 errors in the first place if your site or an external website is linking to the 404 page.
In other words, if I type in your-website-name.com/unicorn-boogers, it won’t show up in your crawl errors dashboard unless I also link to it from my website.
To find the links to your 404 page, go to your Crawl Errors > URL Errors section:
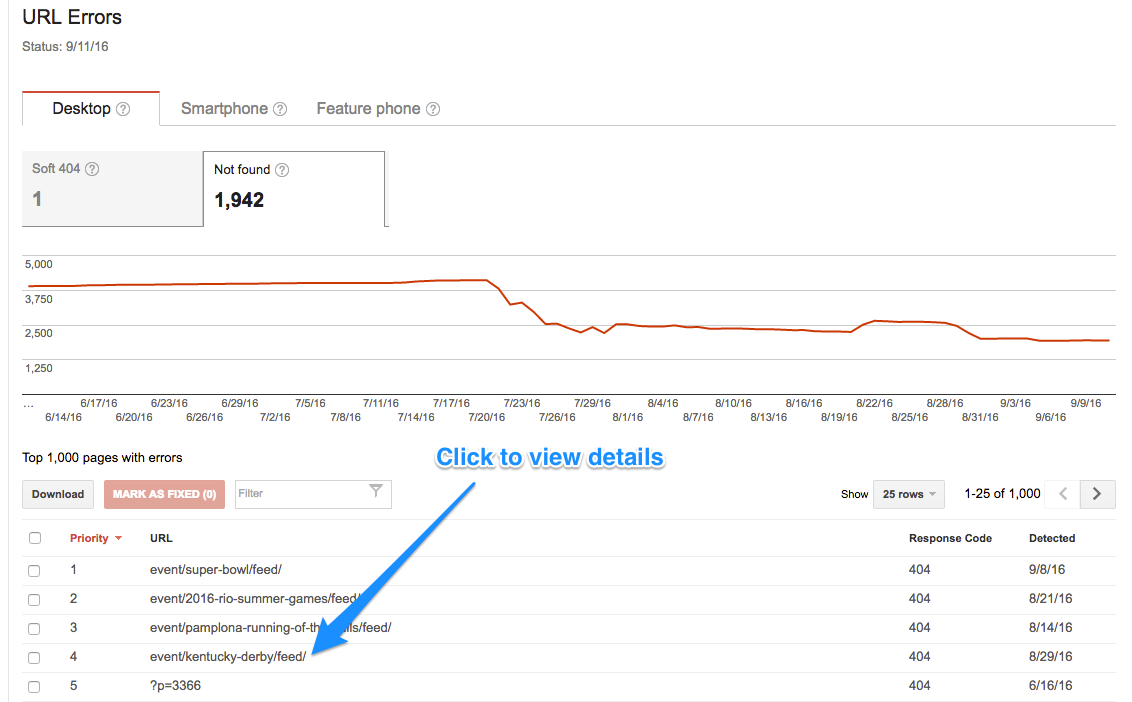
Then click on the URL you want to fix:
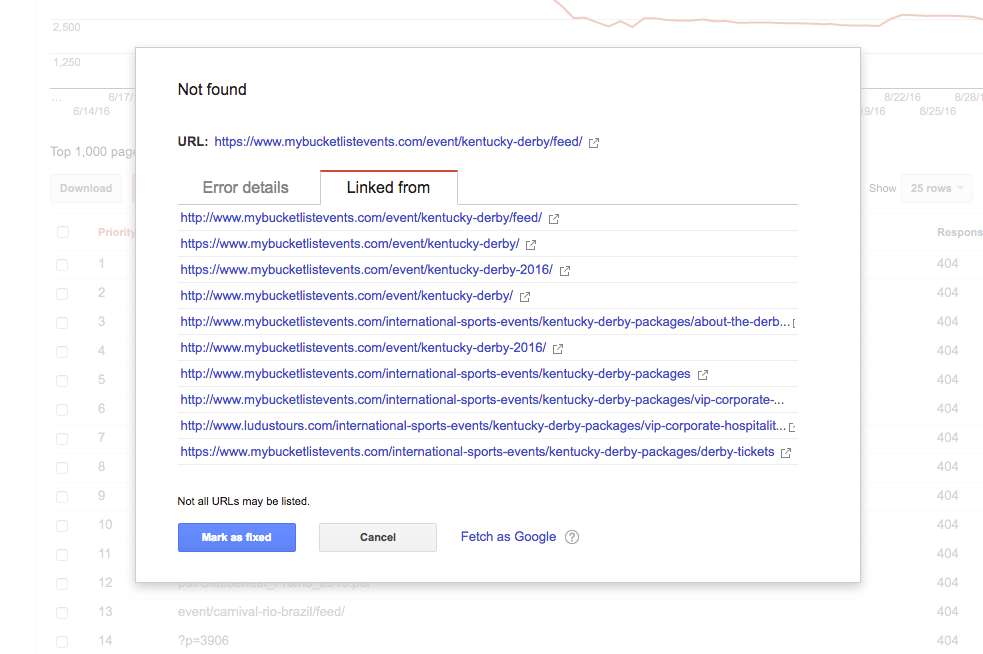
Search your page for the link. It’s often faster to view the source code of your page and find the link in question there:
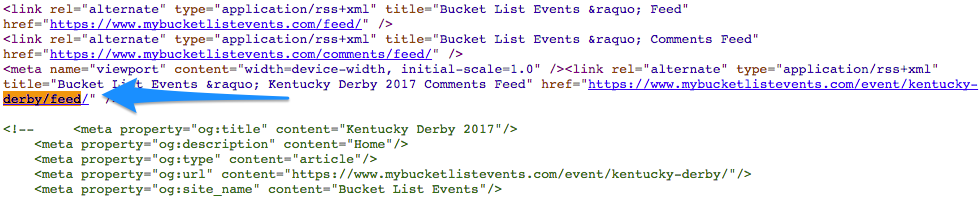
It’s painstaking work, but if you really want to stop old 404s from showing up in your dashboard, you’ll have to remove the links to that page from every page linking to it. Even other websites.
What’s really fun (not) is if you’re getting links pointed to your URL from old sitemaps. You’ll have to let those old sitemaps 404 in order to totally remove them. Don’t redirect them to your live sitemap.
C) Access denied
Access denied means Googlebot can’t crawl the page. Unlike a 404, Googlebot is prevented from crawling the page in the first place.
What they mean
Access denied errors commonly block the Googlebot through these methods:
- You require users to log in to see a URL on your site, therefore the Googlebot is blocked
- Your robots.txt file blocks the Googlebot from individual URLs, whole folders, or your entire site
- Your hosting provider is blocking the Googlebot from your site, or the server requires users to authenticate by proxy
Are they important?
Similar to soft 404s and 404 errors, if the pages being blocked are important for Google to crawl and index, you should take immediate action.
If you don’t want this page to be crawled and indexed, you can safely ignore the access denied errors.
How to fix
To fix access denied errors, you’ll need to remove the element that's blocking the Googlebot's access:
- Remove the login from pages that you want Google to crawl, whether it’s an in-page or popup login prompt
- Check your robots.txt file to ensure the pages listed on there are meant to be blocked from crawling and indexing
- Use the robots.txt tester to see warnings on your robots.txt file and to test individual URLs against your file
- Use a user-agent switcher plugin for your browser, or the Fetch as Google tool to see how your site appears to Googlebot
- Scan your website with Screaming Frog, which will prompt you to log in to pages if the page requires it
While not as common as 404 errors, access denied issues can still harm your site's ranking ability if the wrong pages are blocked. Be sure to keep an eye on these errors and rapidly fix any urgent issues.
D) Not followed
What they mean
Not to be confused with a “nofollow” link directive, a “not followed” error means that Google couldn’t follow that particular URL.
Most often these errors come about from Google running into issues with Flash, Javascript, or redirects.
Are they important?
If you’re dealing with not followed issues on a high-priority URL, then yes, these are important.
If your issues are stemming from old URLs that are no longer active, or from parameters that aren't indexed and just an extra feature, the priority level on these is lower — but you should still analyze them.
How to fix
Google identifies the following as features that the Googlebot and other search engines may have trouble crawling:
- JavaScript
- Cookies
- Session IDs
- Frames
- DHTML
- Flash
Use either the Lynx text browser or the Fetch as Google tool, using Fetch and Render, to view the site as Google would. You can also use a Chrome add-on such as User-Agent Switcher to mimic Googlebot as you browse pages.
If, as the Googlebot, you’re not seeing the pages load or not seeing important content on the page because of some of the above technologies, then you've found your issue. Without visible content and links to crawl on the page, some URLs can’t be followed. Be sure to dig in further and diagnose the issue to fix.
For parameter crawling issues, be sure to review how Google is currently handling your parameters. Specify changes in the URL Parameters tool if you want Google to treat your parameters differently.
For not followed issues related to redirects, be sure to fix any of the following that apply:
- Check for redirect chains. If there are too many “hops,” Google will stop following the redirect chain
- When possible, update your site architecture to allow every page on your site to be reached from static links, rather than relying on redirects implemented in the past
- Don’t include redirected URLs in your sitemap, include the destination URL
Google used to include more detail on the Not Followed section, but as Vanessa Fox detailed in this post, a lot of extra data may be available in the Search Console API.
Other tools
- The Screaming Frog SEO Spider is an excellent tool for scanning your live site and digging up redirect errors. This tool will show you at scale how your redirects are set up, and whether they're properly set as 301 redirects or if they’re set up as something else.
- Moz Pro Site Crawl
- Raven Tools Site Auditor
E) Server errors & DNS errors
Under URL errors, Google again lists server errors and DNS errors, the same sections in the Site Errors report. Google's direction is to handle these in the same way you would handle the site errors level of the server and DNS errors, so refer to those two sections above.
They would differ in the URL errors section if the errors were only affecting individual URLs and not the site as a whole. If you have isolated configurations for individual URLs, such as minisites or a different configuration for certain URLs on your domain, they could show up here.
Now that you’re the expert on these URL errors, I’ve created this handy URL error table that you can print out and tape to your desktop or bathroom mirror.
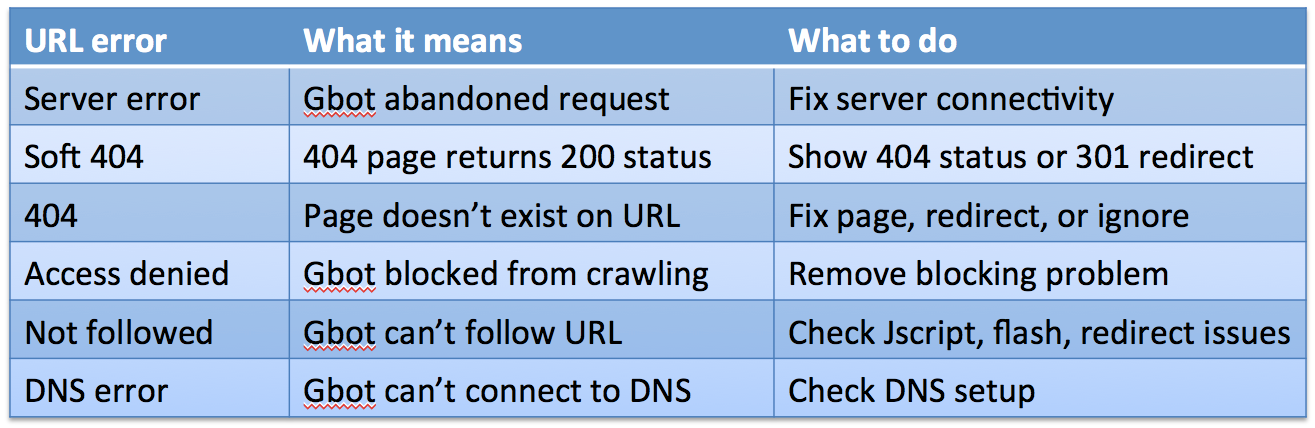
Conclusion
I get it — some of this technical SEO stuff can bore you to tears. Nobody wants to individually inspect seemingly unimportant URL errors, or conversely, have a panic attack seeing thousands of errors on your site.
With experience and repetition, however, you will gain the mental muscle memory of knowing how to react to the errors: which are important and which can be safely ignored. It’ll be second nature pretty soon.
If you haven’t already, I encourage you to read up on Google’s official documentation for Search Console, and keep these URLs handy for future questions:
- Webmaster Central Help Forum
- Webmaster Central FAQs: Crawling, indexing, & ranking
- Webmaster Central Blog
- Search Console Help Crawl Errors report
We're simply covering the Crawl Errors section of Search Console. Search Console is a data beast on its own, so for further reading on how to make best use of this tool in its entirety, check out these other guides:
- The Ultimate Guide to Using Google Search Console as a Powerful SEO Tool
- The Ultimate Guide to Google Webmaster Tools
- Yoast Search Console series
Google has generously given us one of the most powerful (and free!) tools for diagnosing website errors. Not only will fixing these errors help you improve your rankings in Google, they help provide a better user experience to your visitors, and help meet your business goals faster.
Your turn: What crawl errors issues and wins have you experienced using Google Search Console?
Hi Joe,
Thanks for a wonderful article, it almost covered all the aspect of Google Search Console crawl errors, and their fixes.
1) We maintain a tight vigil on our client websites for any errors showing up in Google search console, as we believe it's most reliable method in which Google informs you about how it's looking at your website.
2) We would like to see more details why render or fetch as google failed for a page, it's most annoying thing working with dynamic sites using advanced Jquery, JSOn , Angular JS etc.
3) We use fetch as google more often to check our content is being viewed by Google Bot, and this gives us an idea about how google is viewing our page content.
Thanks,
Vijay
Great uses of Fetch as Google in practice. Agree that the lack of enough information surrounding that tool means that we can't work as fast or as well as we should be able to. Lets hope Google will keep improving!
Hey everyone,
Thanks for reading. A few questions for you:
1) How often do you check the crawl errors in Search Console? What about the other data in Search Console?
2) What are some key missing pieces of information you'd like to see provided by Google in the crawl errors report?
3) Do you use the crawl errors reports in a unique way that most other people don't? Any tips to share?
Hi Joe,
Some interesting questions so thought I'd offer my two cents worth;
1) This really depends on the size of the problem and the size of the site. I work with sites that have mass product turnaround as they are based on weekly trends, sites like this require constant attention on crawl errors as you can easily end up losing some good authority.
On the flipside, we also deal with clients that have a very static website, where there is a minimal amount of change to the architecture or URL structure. In these circumstances we take a glance on a bi-weekly bases as part of our maintenance checks.
2) It would be really handy to know a little bit more about their attempts to crawl errors. We have a 'detected' row but it may be handy to know when something was 'first detected' and 'last detected'. I also see URLs appear that are obviously from previous site builds on that domain, and there is no "linked from" information, or if it is they are also from old pages on the site. My likely guess is that these are still externally linked from somewhere, however I've found instances where I just can't see why Google would attempt to crawl those URLs.
3) My tip for this that some people probably don't do, is to combine your crawl error reports with your log files and analytics data. Take a look to try and understand how many times these errors are being crawled, what was the referring URL and is is just bots that are detecting these. This will help you prioritise what errors to fix first and will help you in discovering the source of such errors.
Great input, totally agree that there's not just one schedule for checking the crawl errors, as every site is different. Hugh sites publishing and making product changes constantly, like Amazon, probably have a team watching them throughout the day!
Agree that more data on the sources of crawl errors would be much more helpful. I had a site where a ton of new errors recently appeared, but they were pulled out from an old sitemap from years ago. From what I can tell, this site earned enough authority in Google's perspective to get a deeper and deeper crawl.
Awesome advanced tactic as well on combining crawl data with log files - sounds like a beastly Excel file!
I personally look into the search console tools once every 30 days unless a client has been having previous issues.
For extra tools in this it would be nice to see broken links in this same report as that can lead to some crawl issues as well.
The crawl report for me is a very useful tool to see exactly how a site is acting to Google. Depending on various errors, or massive 404 lists I can see if there was a site migration that never had the proper redirects put in place or if as you stated some pages that are limiting access to provide a smoother crawl.
Broken links is definitely a good idea. Incoming broken links show up as 404s, but it would be good to have that separated out more clearly. I use Moz, Ahrefs, and Screaming Frog for this, but having it in Search Console would be better.
Site migrations are always a pain, and a massive 404 list is never fun!
Great post here and something that even the most novice person can utilize. I find that not logging in and checking out the search console is a lack of attention for any seo but also for anyone who has a website. The great information right at your fingertips why not use it.
On a closing note I wanted to point out that you gave a great breakdown of the errors what they mean and how to fix them. Thank you for this wonderful contribution to the community.
Thanks for the feedback Tim - glad you enjoyed. Yes it's one of those habits that is so simple, but gets pushed aside for other more important projects. I think the same thing can be said for running an AdWords campaign - if everything seems to be flowing and profitable, why bother? But I think those daily check-ins and preventative 1% fixes add up to a lot in the long run.
Hi All,
Another great tool for spidering your website and finding 404s is 'Xenu.' It's a little ole' fashioned, but so am I! (I know Screaming Frog is probably more technically advanced, and it has been recommended to me countless times)
Yes I've used Xenu in the past and it's great. I've found myself using Screaming Frog primarily, but a lot of SEOs use both. Thanks for reading!
Hi Joe,
Thanks for the detailed breakdown on handling 404 errors on Google Webmaster Tools. It brought some fresh perspective to how I have been handling these 404 errors (putting them to the bottom of my priority pile no more!)
Quick question, you mentioned about setting up alerts and automating the process of identifying and (possibly) solving 404 errors, and I don't think that ended up being talked about in the rest of the article. Would you be creating a follow up article on that? Being able to set up alerts will definitely help SEO peeps to have one less thing to check up on and to add to their daily schedule of things to do.
Thanks again for the great article! (Bookmarking it now!)
Hi Evyk - the best way to set up alerts is directly in the search console preferences area of the dashboard. Other than that there's no great automation that I know of, although there are some advanced strategies you can use by creating dashboards with the API, then hooking that up to another tool like Zapier. I haven't done this myself, but have read about others doing something similar, such as Vanessa Fox. Best of luck!
Informative article Joe! I don't think some people pay attenttion to their crawl errors because they don't realize how detrimental some can be to their site.
Thanks Kristi! Yes they're totally easy to overlook because they require you to go find them in Search Console. Thanks for writing the awesome guide listed in the resources at the end of the post - definitely helped in my research.
Well done and in depth! To reiterate something you talked about with 404 errors. So many of my clients worry when this error comes up but the reality is that is a past SEO or employee writes a post or content that is unrelated or useless in the sense of being spun content or otherwise it is actually a good thing. Let the 404 stand and say "this page is gone for good".
Luckily I have noticed with Google's recent update on 301 and 302 redirects sending more SEO juice through that 404s have equal swiftness in content removal. This is great if you are looking to get rid of old unrelated content. In the same vein it could be bad if you intended to redirect to the correct page and didn't. That is the whole point behind the 404 error is the ability to see content that isn't currently going anywhere and fix it.
Cheers
Totally agree, too many people equate 404 with always bad, but in reality, if the content is actually gone and not worthwhile, the best thing to do is let it 404.
Sometimes, I receive a 404 error of a page that never exists, like index.asp.
Then oftentimes, the 404 I get is from pages index.html and some old pages.
But most of the errors are from pages that never exists.
Have you experienced this?
I think what's most likely is that those pages existed on your site in the past, and are linked to from an old sitemap or other sources. Do you think that's the case? Even old pages from 5+ years ago can show up in the 404s section.
This is a mystery until now. My domain is new and I have never created pages specifically with the file extension .asp. I am using a xml sitemap generated from xml-sitemaps(dot)com website. Maybe it's from them?
Or from links that nobody-knows-why-they-are-linking-to-me through that URL.
Great article! Are you planning "Google News Specific Errors" article?
I haven't dove too deep into news myself, so I didn't touch on that part. Google does have a section at the end of their Crawl Errors guide that could be a good start. Maybe you can write the Google News article!
This is a great content. Should be included in the initial audit before starting the SEO processes.
Thanks Igor - yes it's a crucial part of the SEO process, especially for an initial website audit!
10x Content. Very informative, especially for users like myself who are just getting the hang of the more technical side of SEO.
I'll follow this guide for any crawl errors I receive until I can get more versed in the process. Thanks again!
Thanks Jim - glad to hear you'll be using it to help your process! Let me know if you have any questions on it.
One better solution for fixing 404 errors (see 2.B) is listing all your broken links and mapping 301 redirects to pages that do work. This has become a regular part of my weekly routine. Keeps the indexed pages alive, backlinks working and visits flowing.
100% agree - that's become such a best practice that I didn't want to focus too much on 301's as a solution to 404 errors because it's so prevalent and often used incorrectly. In an attempt to get rid of all 404s, some 301 everything when it's not particularly ideal. But I should perhaps add a note on that point, thanks for the feedback!
Thanks Joe, Thats pretty big article but totallu worth for me. I was good in normal SEO but i am lagging in technical stuff. This helps me to get start with technically.
Regards
Jay
What do you meant by "You’ll have to let those old sitemaps 404 in order to totally remove them."?
Thank you. Thank you Thank you.
I moved my server from shared hosting to a VPS and in the process of doing so, had many issues with server crashes over a few days. It wasn't until 6-7 days later that my organic traffic took a huge dive.
Logged into the search console and had a ton of errors. Just marked them all as fixed and now playing the waiting game to see the impact.
How long does it generally take after marking them as fixed to get re-indexed?
This:
"...
Is hugely critical. I cannot tell you the number of times I've looked through a client's site, trying to figure out a drop in organic traffic and ranking, only to either get told or just eventually sleuth out that during a redesign they had a bunch of 404 errors so they just redirected everything to the homepage.
There are actually WP plugins that will do that as well.
Great article.
Yes I hate when everything gets just redirected to the home page. Such a simple error that can destroy rankings. It's not always their fault, but oftentimes it's the web developer that means well but just doesn't grasp this part of SEO.
Rad post Joe! A nice reminder about how extensive the process is to manage and problem solve crawl errors. Good to know someone like you has all the nitty gritty behind it still.
Great post. Feeling proud to update you since last 5 years from Google Webmaster Tools to Google Search Console. This post is really informative for me. Thanks for sharing with us.
What a comprehensive post to boil down a no. of GWT errors. I think all the problems and the solutions you discussed here are very much constructive and helpful for the Webmasters. And BTW, thanks for letting us know a few of the quick online auxiliaries for detecting drifts around the websites.
Thanks for this comprehensive guide! I feel much better prepared to take full advantage of the tools at my disposal from Google. Will absolutely recommend it to other.
i am suffred for 404 error at my website i will try your advices
it hope that help me learn to manage our Webmaster tool better.
[link removed by editor]
This is a great and digestible break down for someone who is not a developer or SEO tech-savvy. Thank you!
Thanks Chris - happy to have a billionaire commenting on my post!
Nice article. Actually today before reading this article I have found many 404 errors in my GSC for one of the websites and was wondering if ignore them or redirect them. This website was rebuilt about 9 months ago and no proper 301 redirections have been made. Is 9 months enough long time to loose old links authority and so ignore them?
If you still have important traffic or links pointing to your old pages, you should definitely still redirect them. There may be a bit of authority lost depending on who you ask, but a lot of it is still there. Plus beyond the link authority there may be traffic flowing through those links.
It's definitely a balance to figure out which to allow to 404 and which to 301, which is why we're needed!
Very useful thank you.
One thing I would add is that Soft 404s often show ecommerce categories with no products. This could be a good way to identify empty pages on a large site as well as giving an indication on if your site is close to the dreaded Panda.
I found the point you made about old sitemaps. When doing a site migration I tend to just replace the sitemap URL. Do you suggest that I give the sitemap a different URL and let the old one 404 after the redirects have been crawled?
Great point about the ecommerce categories with no products - that would definitely qualify as a soft 404 in some cases. Some ecommerce sites create rules where they'll NOINDEX category pages with no products. Of course, if that's a permanent issue, then the category page should probably just be removed or it'll worsen the user experience.
On sitemaps - in my perspective, it's probably ideal to do what you're doing which is to keep the same sitemap URL. Google crawls the sitemap often, but upon launching of a new site you'll probably want to resubmit the same URL with the new sitemap just to give a little nudge. One downside of keeping the same URL I can foresee is that it would be hard to compare between a new site and old site's pages and their indexing rate. Would be curious to hear if that's been an issue for you?
If you do end up having two different named sitemaps, then yes you would want to allow the old sitemap to 404. This is a good Moz Q&A thread about that issue.
Hi Joe
I love this guide to correct tracking errors in GSC: Very useful. I'll have to try them why there is often not as correct.
Thank you very much for the information
Hi Joe thank for this post.
I don't understand about your robots.txt comment, google tell "You need a robots.txt file only if your site includes content that you don't want search engines to index. If you want search engines to index everything in your site, you don't need a robots.txt file. If you don't have a robots.txt file, your server will return a 404 when Googlebot requests it, and we will continue to crawl your site. No problem".
So I think that if I change content inside my website and I have no robots.txt, google tell "no problem" and will index all the new contet. Why you write "If the Googlebot cannot load your robots.txt, it’s not crawling your website, and it’s not indexing your new pages and changes"? What I missed? Thank you
So if you do have a robots.txt file and want it to be crawled, but Googlebot can't even get to the robots.txt that means that there are larger issues across your site.
Yes, Google crawls the site as normal if a robots.txt doesn't exist. And yes, it's also possible that if your robots.txt can't be crawled for whatever reason, that Google may still be able to crawl the rest of the site. But if it's having trouble loading robots.txt, then it's also likely that it's having trouble with other pages on the site. Does that make more sense?
Hey Joe,
Great article. However, I am getting 403 access denied error after turning off comments on my wordpress site.
The articles that google search console is showing that it can't access are like this: domain.com/article/feed
Any way to fix this?
Much appreciated!
Really great article.. I didn’t know 90% of them. Thank you …:D
Getting problem in website and here in webmaster it show red on DNS and error that googlebot couldn't communicate with server DNS
[Link removed by editor.]
Thank you to share this is very nice post i have one question how to create a Richcard, sitelink and google knowledge graph
Hi! Recently we relaunched a website. In the same time, we passed from http to https. So, now we have in Search Console 2 domains: one with http and one with https. What should we do with the sitemaps from old domain? Should we keep them for the moment? At the moment, the pages from new sitemap are not completely indexed. Thanks!
Hi I Am Getting Lots Of Server Error In URL Error Section ....My Site Is On Wordpress I Am Giving You A List of Error So That You Can See
wp-includes/customize/class-wp-customize-nav-menu-item-setting.php
wp-includes/customize/class-wp-customize-upload-control.php
wp-includes/customize/class-wp-customize-cropped-image-control.php
wp-includes/ms-default-filters.php
wp-includes/customize/class-wp-widget-form-customize-control.php
wp-includes/customize/class-wp-widget-area-customize-control.php
wp-includes/class-wp-customize-panel.php
wp-includes/class-wp-customize-section.php
wp-includes/customize/class-wp-customize-nav-menu-name-control.php
These Are Only Some Examples In My Site There Are Total 153 Url Sever Errors Pls Give Me Soltion How It Can Be Resolve
Hi, great blog post, My question is Google only shows you the top 1000 URL errors each day, is there any way to see a full list of these if you have more.
My site was hacked at the end of last year & although all dodgy data was removed, google is seeing these as missing URL's
How can I mark them as fixed in one go instead of doing them daily.
Thanks
Crawling Errors are necessary to remove otherwise google ignores you..I don't know that my website have crawling error or not but after reading your post now I am going to check weather if there any error exist
How can I fix search page crawl Error?
This case happen since two month ago when I click on crawl error I see hundred of search pages error. I try to make it as fixed but 2 or 3 days later it still show up again.
Ex:
/search/%E5%A4%A7%E5%A5%96%E6%8D%95%E9%B1%BC%E4%BF%A1%E8%AA%89%E5%A5%BD%E5%90%97%E5%9C%BA+Q82019309.com.com/
/search/%E5%A4%A7%E5%A5%96%E6%8D%95%E9%B1%BC%E6%B3%A8%E5%86%8C%E9%80%8168+Q82019309.com.co
/search/%E5%A4%A7%E5%A5%96%E5%A8%B1%E4%B9%90%E8%80%81%E8%99%8E%E6%9C%BA%E9%80%81%E5%BD%A9%E9%87%91+Q82019309.com.com/
Some days ago It appeared several of these errors on my website, I will begin to correct them thanks to your article.
Interesting stuff here. Been looking all over the internet on how to fix it and couldn't find one. Thanks for sharing.
So this has been driving me nuts for weeks. I've made repeated removal requests in Search Console for 404 error pages that Google somehow sees as coming from pages long since gone, including a Yoast WP SEO XML sitemap (I even removed the Yoast plugin months ago). I've been repeatedly requesting removal of all these pages for months now, but they keep popping up as sources for my 404's.
I've run Screaming Frog, Deepcrawl, combed though the site and Google's indexes, and not seeing a trace of these pages anywhere but from inside Search Console...
Glad to read this, Actually i have an idea about the crawl issues and how important it is to sort out ASAP. Thanks for the detail information on this topic, I was actually looking for post like this
Indeed a post worth reading... Learned lots of stuff from this post.
Anyway, I've a problem for which i couldn't locate a suitable solution from your post.
I've marked a number of link errors as fixed few days ago. I just made 301 redirects. But due to an unknown error in my platform, those redirects are somehow broken. So I'm just wondering how may I find those links again, as Google Search Console no longer shows those links as errors.
They should come up again in the next few days or weeks depending on the size of your site! Google crawls more important sites faster, so keep an error on your crawl rate and look out for those again. You should also scan your site with Screaming Frog!
I always have some URL errors there from old pages that i've deleted and I just go in and manually remove the error.
It might be handy to edit your post and add in that you can manually remove the error if you've fixed the problem yourself!
Hey Marky - do you mean removing the error from the Search Console dashboard? I think I covered what you're talking about in the "Tip: Going crazy with the amount of errors? Mark all as fixed." section, but yes you can do that individually too as you mentioned!
Nice Work Joe, This post is very informative. I have been trying to use different plugins from time to time just to check which one is the most effective. You are welcome to write on my blog https://growthvibe.com
Hi guys,
Just now I'm on a migration for a client and we have been hit for lots of 404, so we have to do this over and over ;)
HI Joe i got crawl errors in search console but now i think i can solve it. Thank you
Detailed and too technical post which many folks some time by pass thier daily SEO routine. I am sure many do keep and eye on these but skip them by considering these errors are the nromal with less priority.
Well suggested solutions and method how to deal with them and in which order.
perfectly written.
Thank you for sharing this valuable article. But I have a few queries, in my site I didn't found any errors still my website has crawling errors. Is there any unknown errors to fix for crawling frequently?
Thank you very much for this information, I always use search console to check all errors and always show them to our programers to fix them. But now I know how to manage them individualy and it is not so difficult to do. Every week I check our website projects for errors just for instanc or when the clients require the detailed report on diferent errors. With this article I can explain everything to all of them.
There were many errors when we redirect through 301 some of the pages or when we change from http to https, and these errors I always see there, even if I fix them. Why it happens? maybe to insert or to "announce" google that we made redirection. I just added another/correct link (https) to console and now it undersands better. But the previous one (with http) remains in my list.
Yes moving from http to https does bring up another set of issues. It's always good to verify all version of your site in search console, include the https versions. Not sure if you were asking a question at the end there or just sharing what you found!
Very informative sharing. As a newbie i didn't understood why it shows me 4 soft errors, you make clear. thank you
I have WordPress and use some of their plugins to detect errors on my site, but I know it'd be better to just use the Search Console! A bit of a learning curve, but I will definitely check it out. Thanks
Hi Joe,
Thank you for you guide, It has helped me to understand and solve problems.
Regard
best article ever, i am facing this issue with azcar.ae now understand things hows to tackle. Thanku
Glad it helps!
Just by clicking on "Mark as fixed" will not solve your problem. Google wil still try to crawl those pages again . It is better to redirecting them to homepage and then click as "Mark as fixed"
Sorry - this is not correct. Redirecting all 404 pages to your homepage it will generate tons of "soft 404" errors in the search console. If these pages are gone, and you have no internal links pointing to them anymore it's better to just let them 404 or 410. If you have a similar page on your site covering the same topic, in that case you could redirect the 404 to the similar page.
Agreed with Dirk
@Manjesh - I used Mark as fixed as a way to show only the newest problems. Sometimes there are 404s that have since been corrected that you want to remove from that dashboard. Of course clicking that button doesn't fix them for you!
Hi Joe,
Great information. We Should be audit website issues in Google webmasters tool before starting the SEO processes.
Thanks for this cool blog. I will see how to correct my errors now. https://globalchemicalsltd.com/
Thank you for this information i have linked this article to a customer today you saved me a lot of time!
Kind Regards Brady BlueSEORank.com Cheapest SEO Online